
日常巡检
最近更新时间: 2025-10-11 18:10:00
- 运维巡检总览
| 标号 | 巡检项 | 说明 |
|---|---|---|
| 1 | 日常巡检项列表 | 日常巡检项概览 |
| 2 | 检查监控控制台 | 查看监控基本功能是否正常 |
| 3 | 检查zookeeper状态 | 查看zookeeper是否正常 |
| 4 | 检查Kafka状态 | 查看kafka是否正常 |
| 5 | 检查Elasticsearch状态 | 查看Elasticsearch是否正常 |
| 6 | 检查Flink状态 | 查看Flink是否正常 |
| 7 | 检查其他pod状态 | 查看其他模块是否正常 |
| 8 | 检查其他模块 | 查看依赖是否正常 |
 2. 检查监控控制台
登录租户端控制台,查看监控是否正常。具体操作可参考《租户端操作手册》。
2. 检查监控控制台
登录租户端控制台,查看监控是否正常。具体操作可参考《租户端操作手册》。
- 前提条件: 已获取租户端账号。
- 操作步骤: 登录租户端云监控控制台,查看云产品的监控数据和告警列表。
- 检查结果:
- 正常:页面无报错,监控数据和告警列表可以正常展示。
- 异常:页面有报错,或无监控数据。
- 异常处理: 按照《运维手册》中故障处理章节进行排查与处理。
- 运维经验: 无。
- 检查zookeeper状态 登录zookeeper部署机器,检查zookeeper是否正常。
- 前提条件: 已获取zookeeper部署机器ip和登录密码。
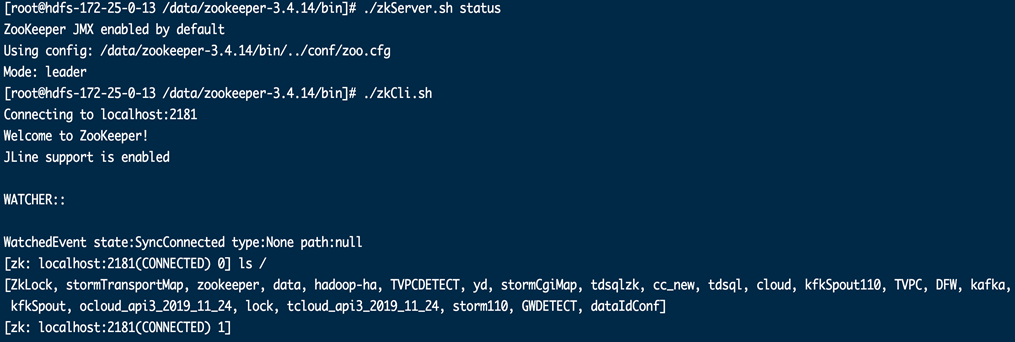
- 操作步骤: 登录所有ZK节点,找到zookeeper安装目录(默认/usr/local/services/zookeeper),进入bin目录,运行./zkServer.sh status。所有节点无错误输出,除了follower外,有1个leader,则zk集群是运行正常的。 进入bin目录下,运行./zkCli.sh,运行 ls / ,查看目录信息。
- 检查结果:
- 正常:返回的目录中有 /storm110,/kafka , /kfkSpout。
- 异常:返回的目录中缺失 /storm110,/kafka , /kfkSpout。缺失目录则标明对应的组件存在异常(以上目录对应的组件依次为 storm,kafka,storm)。
- 异常处理: 若zookeeper进程不存在,则进入bin目录,运行sh zkServer.sh start将zookeeper重新拉起。
- 运维经验: Zookeeper部署节点需要加上crontab,当进程挂掉后自动拉起。

- 检查kafka状态 登录zk和kafka节点,检查kafka状态是否正常。
- 前提条件: 已获取zk节点和kafka节点登录信息。
- 操作步骤: 进入zk部署的bin目录下,运行zkCli.sh,运行 ls kafka/kafka/brokers/ids。
- 检查结果:
- 如果返回[1, 2, 3]或[0,1,2] 则表示有3台kafka节点在运行中,如果缺少,有可能节点有异常,但不一定影响服务,但仍需尽快修复。
- 如果上述命令返回少于3个,说明有节点异常,执行get kafka/kafka/brokers/ids/0,可以得到节点ip信息(id的编号从上边的返回结果取),将返回的id依次执行,跟kafka部署的ip对照,既可知道异常的kafka节点信息。
- 异常处理: 登录异常的kafka节点,ps -ef|grep kafka查看进程是否存在,如不存在,进入bin目录,执行sh kafka-server-start.sh则重新拉起。
- 运维经验: Kafka节点部署机器应加上crontab,如进程挂掉则自动拉起。
- 检查Elasticsearch状态 检查Elasticsearch状态是否正常。
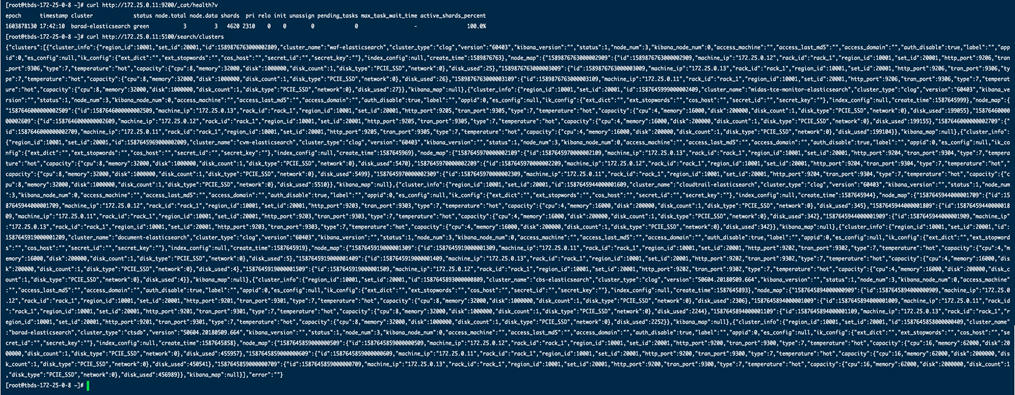
- 操作步骤: curles1.barad:9200/_cat/health?v,查看返回的status是否为green。 curles1.barad:5100/search/clusters, 查看返回结果中当前集群的磁盘使用量。
- 检查结果:
- 正常:集群状态为green, 当前集群的disk_used / capacity.disk <= 0.8。
- 异常:集群状态为red或yellow,当前集群的disk_used /capacity.disk > 0.8。
- 异常处理: 集群状态为red和yellow可能是es的node故障,需要登录node查看进程是否挂掉,如果挂掉需要执行./bin/elasticsearch重新拉起。 集群disk_used /capacity.disk > 0.8,表明集群容量不足,需要进行扩容。
- 运维经验: 将Elasticsearch节点的磁盘使用率监控起来。

- 检查Flink状态 检查Flink状态是否正常。
- 操作步骤:
登录机器yarn访问入口,如10.19.0.34:8088
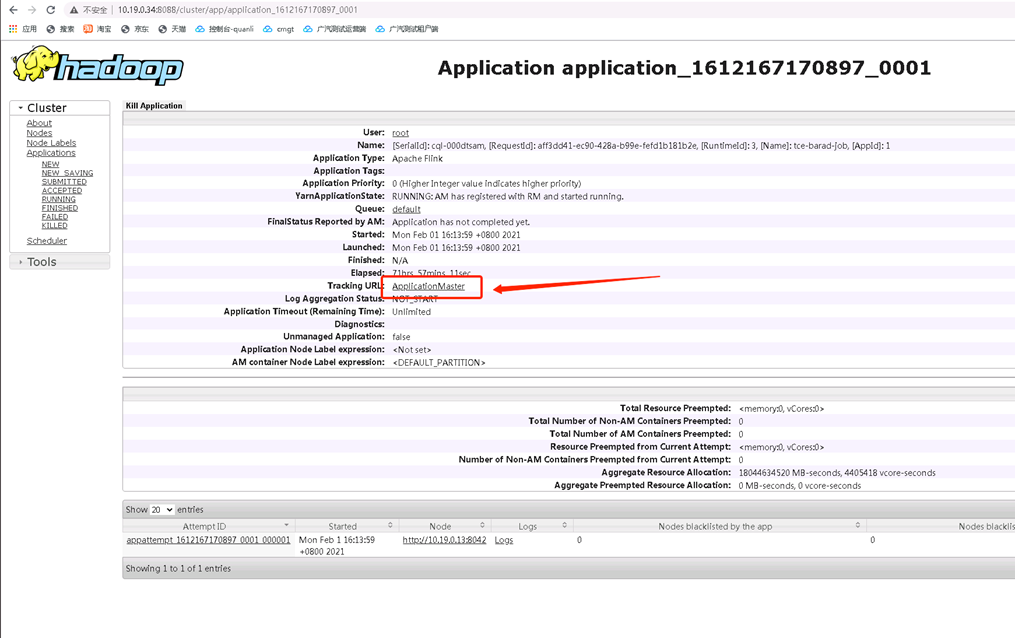
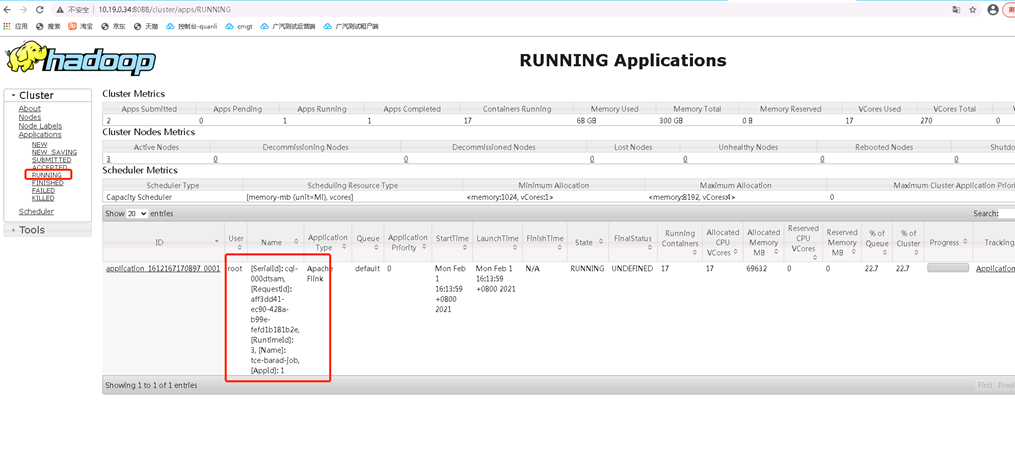
 可以看到状态,运行时间,启动时间等
查看数据流向:
可以看到状态,运行时间,启动时间等
查看数据流向:
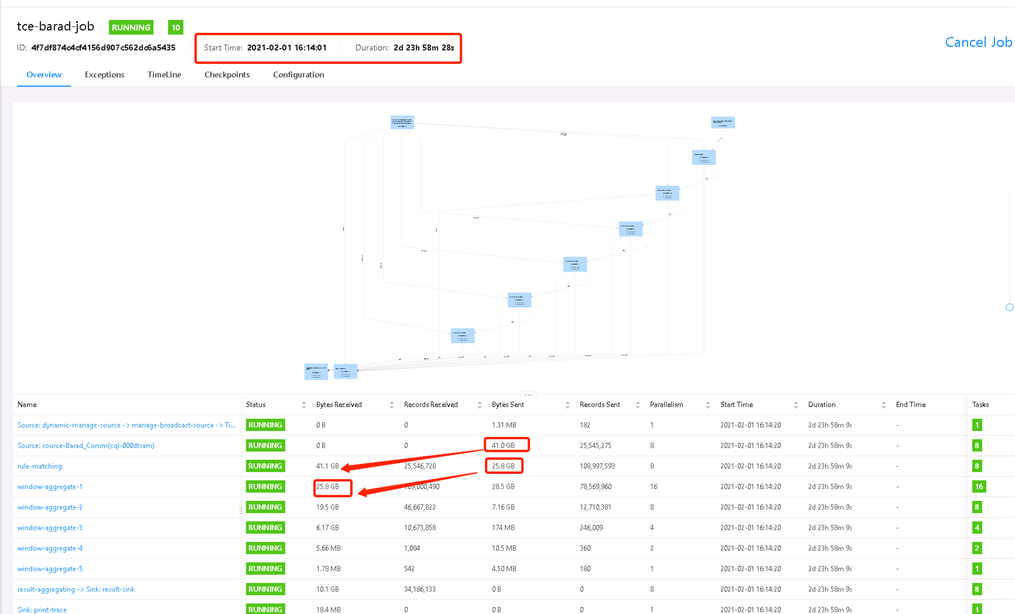
- 检查结果:
- 正常:页面无报错,Status running ,数据流向有数据。
- 异常:页面有报错,或 Status 不是 running。
- 异常处理:
如页面有报错,查看页面日志。
如数据流向Status 不是 running ,重新提交任务。在master节点进入到barad-skywalker ,cd /usr/local/services/barad-skywalker/job,执行 sh run-job.sh
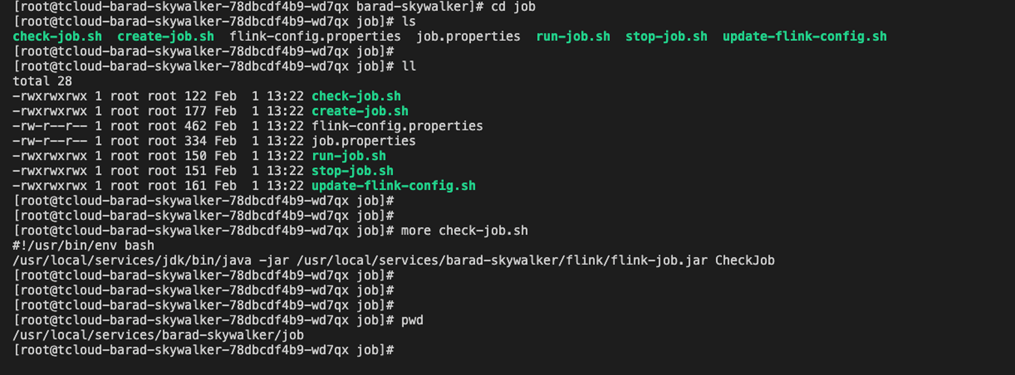
- 运维经验: /usr/local/services/barad-skywalker/job 目录下放了检查、创建、停止 flink任务的脚本。


 可以看到状态,运行时间,启动时间等
查看数据流向:
可以看到状态,运行时间,启动时间等
查看数据流向:


- 检查其他pod状态 登录tcs-master主机,查看barad相关pod是否正常。
- 前提条件: 已获取tcs-master主机登录信息。
- 操作步骤: 登录tce-master主机。 执行命令’kgtcloud-barad’,查看pod是否是running状态。
- 检查结果:
- 正常: barad相关pod都在运行中。
- 异常:barad相关的pod有非运行中的状态。
- 异常处理: 查看异常pod的日志和事件信息,根据事件信息进行处理。
- 运维经验: 查看如果遇到异常pod,可以尝试重启pod。