
扩容指导
最近更新时间: 2025-10-11 18:10:00
pod扩容
- 扩容依据 除去ZK,Kafka,ES为物理机部署,Barad组件均为无状态服务,已全部容器化部署,只需根据资源使用率进行扩容即可: 当资源使用率大于80%需进行扩容。 由于负载过高导致pod频繁重启需进行扩容。
- 扩容操作 进行自动扩缩容,同时修改部署yaml的replica个数。
HDFS+Yarn扩容
操作前检查
注意:
操作前要检查 hdfs是否丢数据;
是否可正常读写;
是否重启active namenode ;standby可正常切换成为 active。
- 检查集群的namenode 主备是否正常: hdfs haadmin -getServiceState namenode1 hdfs haadmin -getServiceState namenode2
- 确保dn的数量恢复到演练前和集群无丢数据。 hadoop dfsadmin -report
- 确保当前hdfs集群可读可写: hadoop fs -put ./本地文件 /tmp/xxx hadoop fs -get /tmp/xxx ./xxnew
扩容操作
- 登录物料机。进入hdfs物料目录,备份原来的host信息和变量信息: xxx/product-tcenter-support-hdfs/config]#cp vars.yml vars.yml.bak; cp hdfs_hosts hdfs_hosts.bak
- 修改var.yml文件,根据现场实际情况修改:
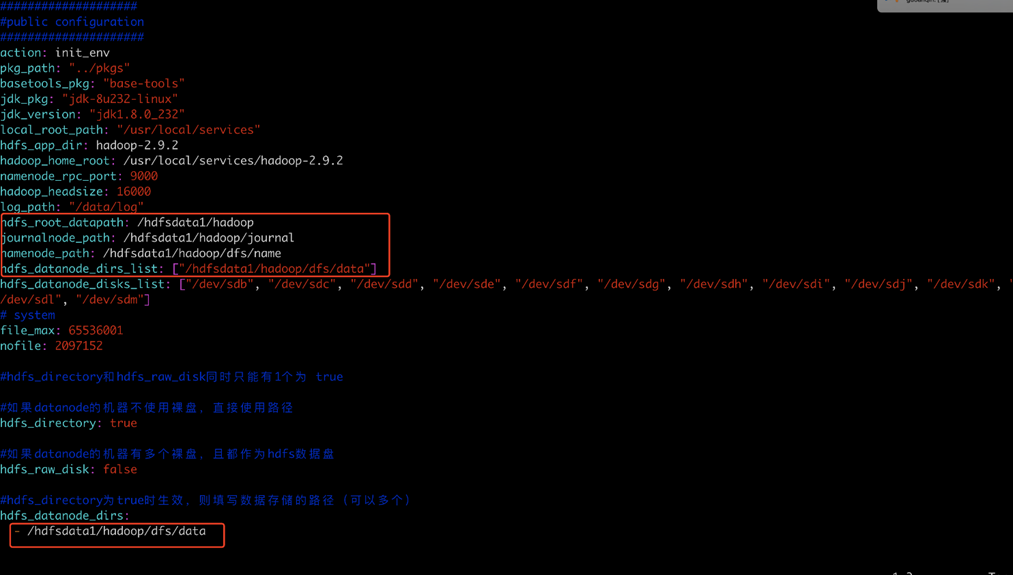
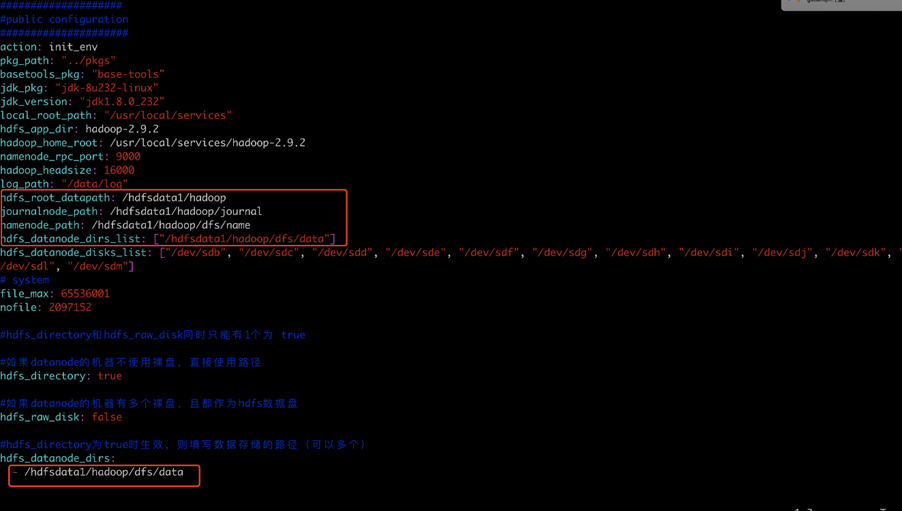
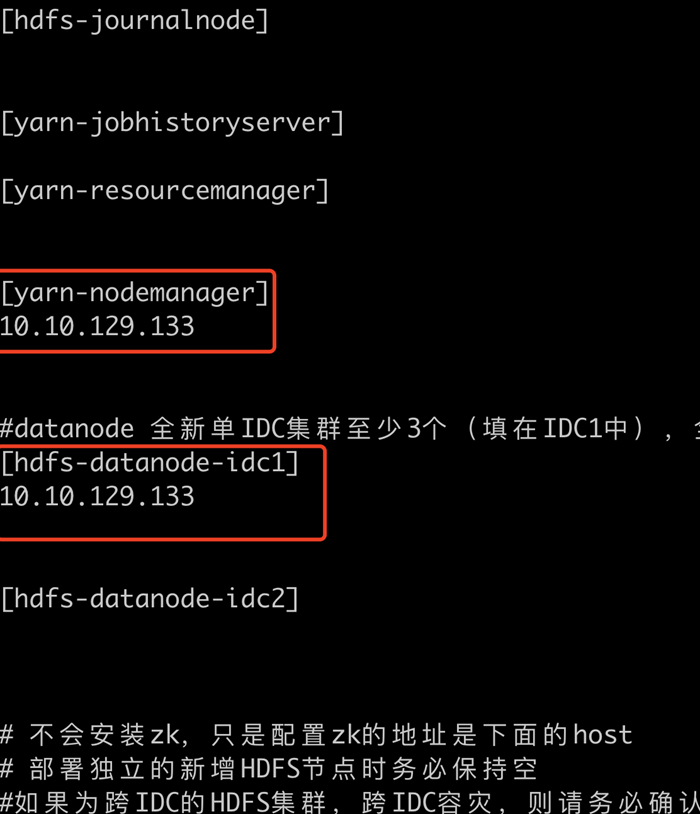
- 修改hdfs_hosts 文件,按照扩容datanode节点的方式来扩容新的节点(把所有的机器ip写入到 idc1中和nodemanager),其他 server role的ip都要清理干净:
- 备份文件:hdfs_install.yml product-tcenter-support-hdfs]# cpTCE/ansible/scripts/hdfs_install.yml TCE/ansible/scripts/hdfs_install.yml.bak
- 注释掉所有启动服务的步骤:(正常 294行 start journalnode以后所有的任务都要注释)

- 登录物料机相关物料目录,执行如下命令:(把前三步的vars.yml和hdfs_hosts文件复制到) xxxx/product-tcenter-support-hdfs/TCE/ansible/scripts]# cp../../../config/vars.yml ./ xxxx/product-tcenter-support-hdfs/TCE/ansible/scripts]#cp ../../../config/hdfs_hosts ./ xxxx/product-tcenter-support-hdfs/TCE/ansible/scripts]#ansible-playbook -i hdfs_hosts hdfs_install.yml
- 复制老hdfs集群nn的配置到扩容的机器 登录新机器,依次拷贝老机器 hadoop包到新机器: cd/usr/local/services scp-P36000 -r old-hdfs-ip-nn1:/usr/local/services/hadoop-3.2.1/etc/usr/local/services/hadoop-3.2.1/ scp-P36000 -r old-hdfs-ip-nn1:/usr/local/services/Hadoop-3.2.1/check_* /usr/local/services/hadoop-3.2.1/
- 登录新扩容的机器,启动datanode和nm服务:
/usr/local/services/hadoop-3.2.1/sbin/hadoop-daemon.sh start datanode
/usr/local/services/hadoop-3.2.1/sbin/yarn-daemon.shstart nodemanager
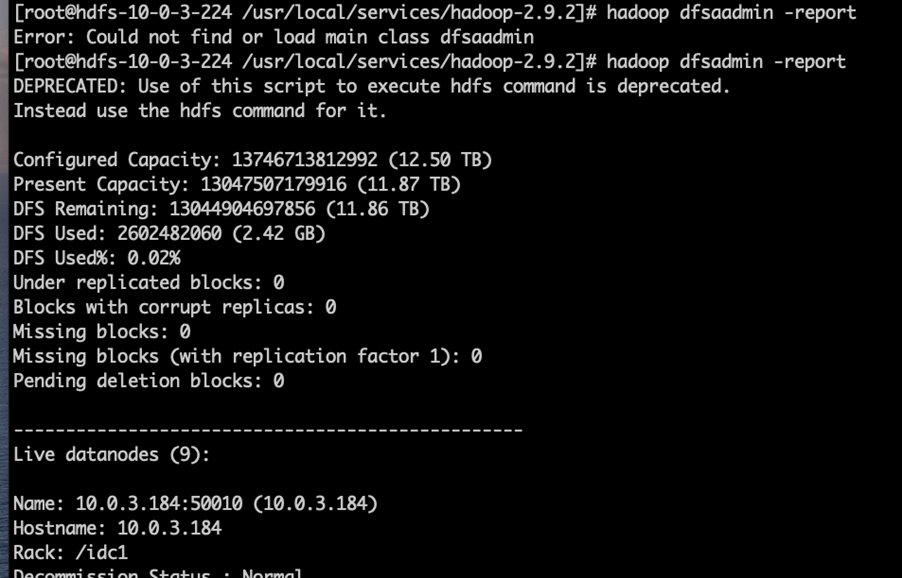
执行如下命令确保扩容的 新机器都正常启动并加入集群,确保新机器的ip都正常加入
hadoopdfsadmin -report
缩容操作
- 登录hdfs的两个 nn节点执行如下操作:
/usr/local/services/hadoop-2.9.2]# vim etc/hadoop/excludes_datanodes
将老hdfs的三台机器ip写入该文件中;
执行如下命令(两台nn都添加上述老hdfs ip后,到一台nn执行如下命令即可):
hdfs dfsadmin -refreshNodes
随后执行如下命令按照下述截图检查是否相应的机器处于 Decommission in progress 状态,直到decommissioned 状态
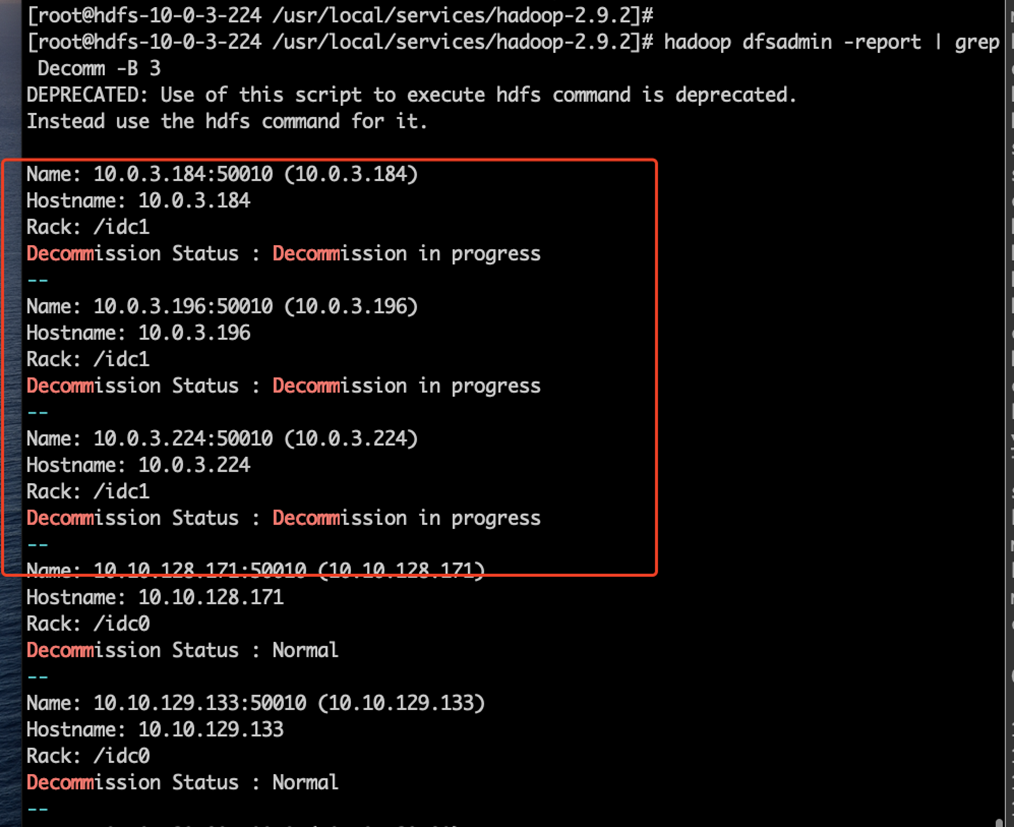
- 登录 resourcemanager 的两台机器,执行如下操作:
cat /usr/local/services/hadoop-3.2.1/etc/hadoop/excludes_nodemanagers
hdfs-10-10-129-133
10.10.129.133
添加要下线的机器ip ,如果是主机名,则把主机名也写上


- 登录hdfs的两个 nn节点执行如下操作:
/usr/local/services/hadoop-2.9.2]# vim etc/hadoop/excludes_datanodes
将老hdfs的三台机器ip写入该文件中;
执行如下命令(两台nn都添加上述老hdfs ip后,到一台nn执行如下命令即可):
hdfs dfsadmin -refreshNodes
随后执行如下命令按照下述截图检查是否相应的机器处于 Decommission in progress 状态,直到decommissioned 状态
检查
- 检查集群的namenode 主备是否正常: hdfs haadmin-getServiceState namenode1 hdfs haadmin-getServiceState namenode2
- 确保dn的数量恢复到演练前和集群无丢数据 hadoop dfsadmin-report
- 确保当前hdfs集群可读可写: hadoop fs -put./本地文件 /tmp/xxx hadoop fs -get/tmp/xxx ./xxnew
barad flink-yarn扩容
说明:
该扩容方案是基于新增物理机的方式,如果不需要新增物理机,仅仅只是修改flink的任务配置,只需要运行扩容脚本即可。
- 增加underlay的cvm的资源
- yarn扩容
- 进入到tcloud-barad-skywalker容器中,注释掉flink的corn检查任务

- 完成yarn的扩容,参考以下10.2章节完成:
- 进入到tcloud-barad-skywalker容器中,注释掉flink的corn检查任务
- 停掉flink的任务
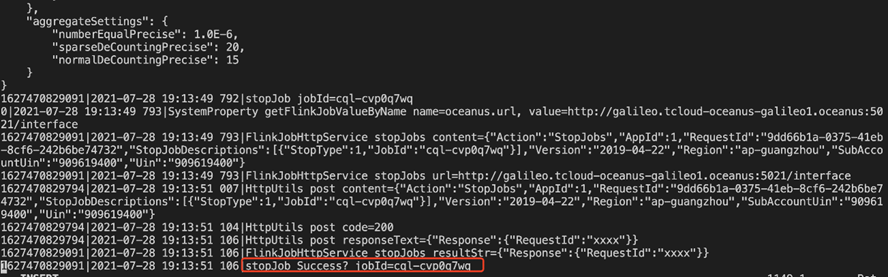
运行stop-job.sh的脚本,执行成功后,记录运行脚本的毫秒时间戳,用于补算的任务开始的时间戳,查看flink-job.log的任务日志,可以看到如下的图,即代表成功停掉任务。
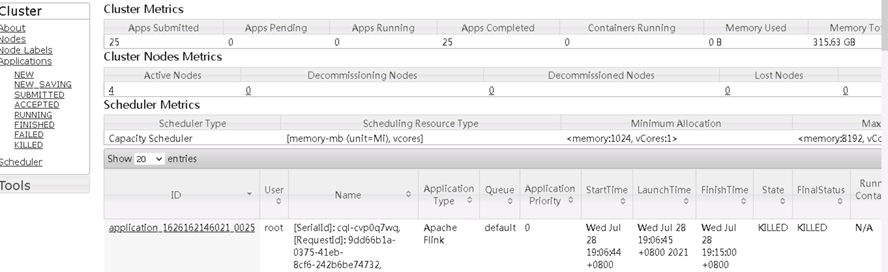
 同时在hadoop的页面可以看到任务已经被kill掉
同时在hadoop的页面可以看到任务已经被kill掉
- 扩容flink任务
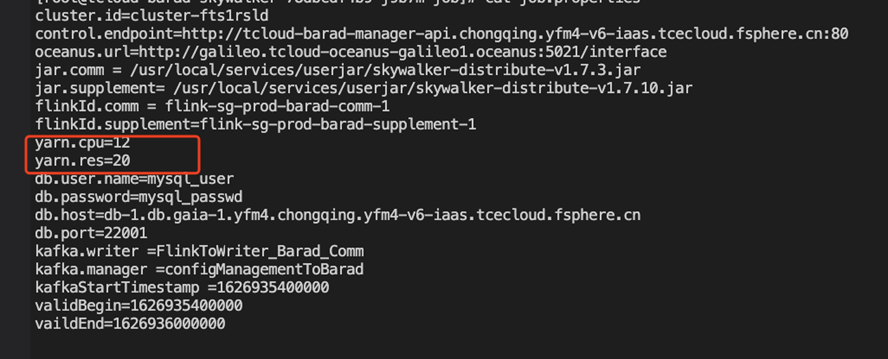
- 根据扩容后的yarn配置,修改job.properties中yarn.cpu和yarn.res的数字,其中yarn.cpu代表整个yarn的cpu核数,yarn.res代表最大使用的百分比数字。
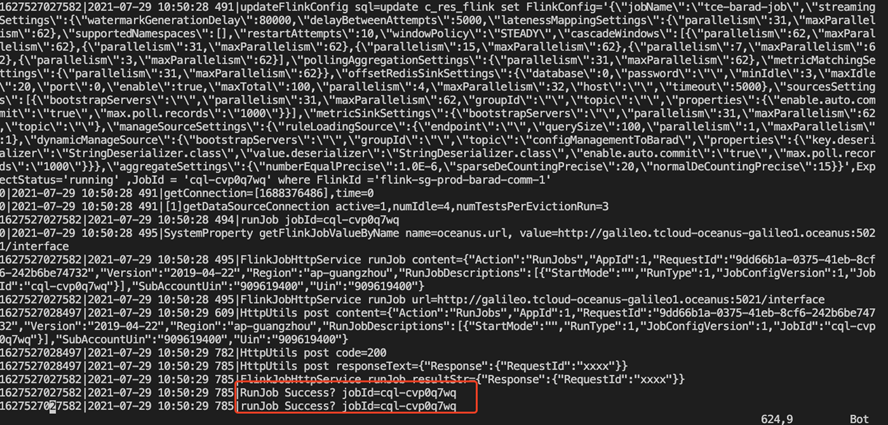
- 运行scale-flink-config.sh脚本,执行扩容flink的运算配置,数据库manager的c_res_flink可以看到修改后的配置,扩容会启动流,查看日志,看到扩容后的配置,扩容成功的success的日志。
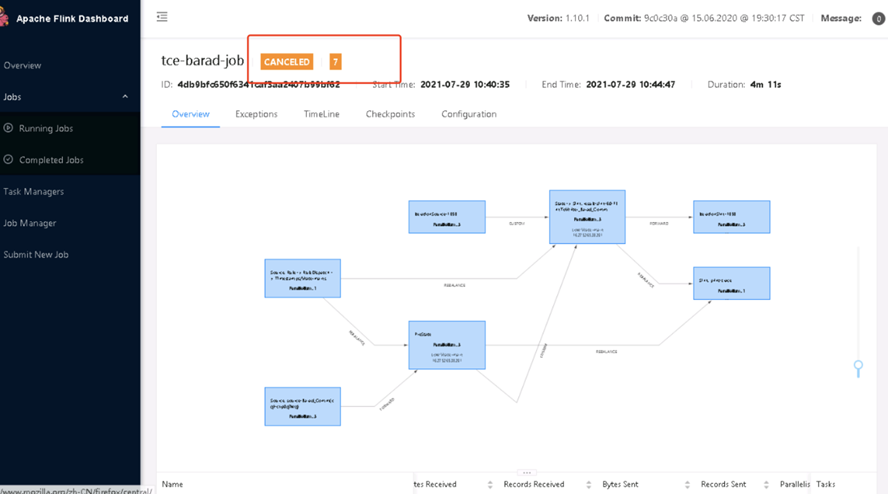
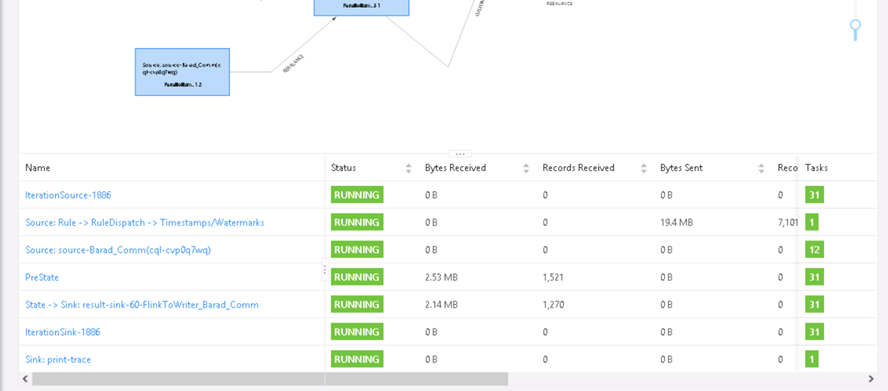
- 在hadoop的页面可以看到扩容后的作业处于running状态,flink-ui看到任务正常执行,可以看到如下的图,则代表扩容成功。记录运行成功的毫秒时间戳,作为运行补算任务的结束时间戳。
- 根据扩容后的yarn配置,修改job.properties中yarn.cpu和yarn.res的数字,其中yarn.cpu代表整个yarn的cpu核数,yarn.res代表最大使用的百分比数字。
- 完成补算任务 根据第三步和第四步得到的起始毫秒时间戳,完成补算任务。









 同时在hadoop的页面可以看到任务已经被kill掉
同时在hadoop的页面可以看到任务已经被kill掉





