
故障处理思路
- Apm指标数据链路:
Apm通过collector组件,将指标数据上报到barad-nws,barad-nws对维度信息翻译以后缓存到kafka,kafka数据流入到flink,flink再将数据计算结果流入kafka,kafka再将数据写入writer,writer写入es,客户在前端查看数据,调用api,api从es拉取数据展示。 - 告警链路:
创建了告警策略之后,同步器会去同步告警策略和告警规则到adp告警检测,adp告警检测会从第二层kafka获取监控数据进行检测是否符合告警规则,符合则到amp告警发送,amp告警发送发送消息给到客户,并且将告警历史等信息存到es保存。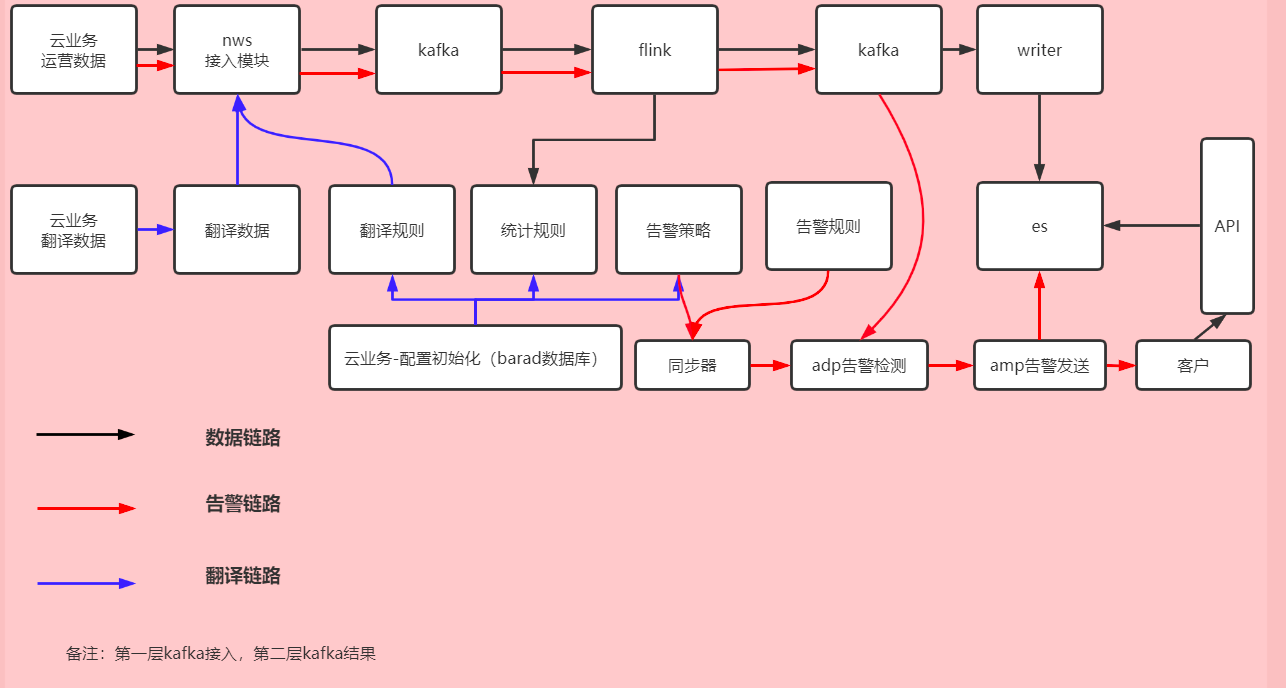
- 排查思路:
- 分析具体场景,缩小范围。
- 针对具体case分析。
- 全链路分析,逐一排查。
- Apm指标数据链路:
故障处理CASE
指标无监控数据
- 排查思路:
根据数据链路去查每一个组件。 - 故障现象:
租户端控制台所有产品都看不到监控数据。 - 故障定位及处理:
- 检查ES集群是否正常部署:
- 在pod内curles1.barad:9200/_cat/health?v,如果集群状态为green则正常。
- 查看存储表是否正常初始化:
- curl es1.barad:9200/_metrics,正常应返会viewName index的集合,若报无权限或无该index,则创建集群的初始化参数有问题,开启了鉴权,或集群类型创建的不是ctsdb,需将集群销毁重新创建,具体可参考ctsdb oss部署文档。
- 查看建表的时间戳格式是否正常:curl es1.barad:9200/_metric/cvm_device-60,若返回的format为epoch_second则为正常,若为epoch_mills则为异常。如异常需要将该表删掉重建(如管控刚刚拉起,存量数据无需保留的话,可将所以metric删掉后重新执行初始化脚本)。
- 如以上都正常,且集群本身运营有一段时间后突然没数据,可查看es存储是否被写满,
- curl es1.barad:9200/cat/allocation?v的disk.indices可查看当前已使用的node空间,
- curl es1.barad:5100/_search/clusters可以看到对应集群预先分配的node磁盘空间。如已达到分配容量,则需要对ES进行扩容。
- 排查思路:
拓扑图无数据
- 排查思路:
这种情况可以肯定的是taw-streaming组件那个的链路存在问题, - 故障现象:
拓扑图无数据,无法生成关系图。 - 故障定位:
- 确认上报方collector组件是否有写入kafka数据中。
- 如确实有写入,检查streaming的任务是否有丢弃数据,过滤。
- 如没有,检查writer-trace是否正常消费写入es中。
- 运维经验:
- 集群的初始化操作一定要做。
- 配置的管理切记不要搞错。
- 排查思路:
业务无告警
- 告警架构:
监控中台将告警能力分为检测和告警
- 告警架构:



- 告警组件:
同步组件tcloud-barad-alarm-synchronizer
告警发送tcloud-barad-alarm-amp
告警检测tcloud-barad-alarm-detector
库 StormCloudConf,alert_management_platform_new,manager。
- 数据同步逻辑:
1. 查看是否有监控数据,若无监控数据,则先按照《无监控数据》进行定位。
2. 若有监控数据但无告警,则需要查看告警组件的日志,根据日志报错进行排查。