
操作场景
分隔符提取模式适用于日志文本中每行内容为一条原始日志,且每条日志可根据指定的分隔符提取为多个 key-value 键值的日志解析模式。若不需要提取 key-value,请参见 单行全文格式 进行配置。本文为您介绍如何使用分隔符提取模式采集日志。
前提条件
- 目标文件所在服务器或自建 K8s 已安装 LogListener。
- LogListener 版本为2.4.5以上。
效果预览
假设您的一条日志原始数据为:
10.20.20.10 - ::: [Tue Jan 22 14:49:45 CST 2019 +0800] ::: GET /online/sample HTTP/1.1 ::: 127.0.0.1 ::: 200 ::: 647 ::: 35 ::: http://127.0.0.1/
当日志解析的分隔符指定为:::,该条日志会被分割成八个字段,并为这八个字段定义唯一的 key,如下所示:
IP: 10.20.20.10 -
bytes: 35
host: 127.0.0.1
length: 647
referer: http://127.0.0.1/
request: GET /online/sample HTTP/1.1
status: 200
time: [Tue Jan 22 14:49:45 CST 2019 +0800]
操作步骤
步骤1:登录控制台
- 登录日志服务控制台。
- 在左侧导航栏中,单击日志主题,进入日志主题管理页面。
步骤2:创建日志主题
- 单击创建日志主题。
- 在弹出的对话框中,输入相关信息,单击确定,即可新增日志主题。
步骤3:机器组管理
- 日志主题创建成功后,进入该日志主题管理页面。
- 选择采集配置页签,在 LogListener 采集配置中单击新增,并在服务器及应用栏中选择分隔符 - 文件日志。
- 在机器组管理页面,勾选需要与当前日志主题进行绑定的机器组,单击下一步。
步骤4:采集配置
在采集配置页面,填写采集规则名称,并根据日志采集路径格式填写“采集路径”。
日志采集路径格式:[目录前缀表达式]/**/[文件名表达式]。
填写日志采集路径后,LogListener 会按照**[目录前缀表达式]匹配所有符合规则的公共前缀路径,并监听这些目录(包含子层目录)下所有符合[文件名表达式]**规则的日志文件。其参数详细说明如下:
| 字段 | 说明 |
|---|---|
| 目录前缀 | 日志文件前缀目录结构,仅支持通配符 * 和 ? - * 表示匹配多个任意字符 - ? 表示匹配单个任意字符 - 不支持填写逗号 |
/**/ |
表示当前目录以及所有子目录 |
| 文件名 | 日志文件名,仅支持通配符 * 和 ? , - * 表示匹配多个任意字符 - ? 表示匹配单个任意字符 - 不支持填写逗号 |
常用的配置模式如下:
[公共目录前缀]/**/[公共文件名前缀]*[公共目录前缀]/**/*[公共文件名后缀][公共目录前缀]/**/[公共文件名前缀]*[公共文件名后缀][公共目录前缀]/**/*[公共字符串]*
填写示例如下:
| 序号 | 目录前缀表达式 | 文件名表达式 | 说明 |
|---|---|---|---|
| 1. | /var/log/nginx | access.log | 此例中,日志路径配置为 /var/log/nginx/**/access.log, LogListener 将会监听 /var/log/nginx 前缀路径下所有子目录中以 access.log 命名的日志文件 |
| 2. | /var/log/nginx | *.log | 此例中,日志路径配置为 /var/log/nginx/**/*.log,LogListener 将会监听 /var/log/nginx 前缀路径下所有子目录中以 .log 结尾的日志文件 |
| 3. | /var/log/nginx | error* | 此例中,日志路径配置为 /var/log/nginx/**/error*,LogListener 将会监听 /var/log/nginx 前缀路径下所有子目录中以 error 开头命名的日志文件 |
注意
- Loglistener 2.3.9及以上版本才可以添加多个采集路径。
- 建议配置采集路径为
log/*.log,rename日志轮转后的老文件命名为log/*.log.xxxx。- 默认情况下,一个日志文件只能被一个日志主题采集。如果一个文件需要对应多个采集配置,请给源文件添加一个软链接,并将其加到另一组采集配置中。
配置采集路径黑名单
开启采集路径黑名单,可在采集时忽略指定的目录前缀或完整的文件路径。目录路径和文件路径可以是完全匹配,也支持通配符模式匹配。
采集黑名单分为两类过滤类型,且可以同时使用:
- 文件路径:采集路径下,需要忽略采集的完整文件路径,支持通配
*或?,支持**路径模糊匹配。 - 目录路径:采集路径下,需要忽略采集的目录前缀,支持通配
*或?,支持**路径模糊匹配。注意:
- 需要 LogListener-2.3.9及以上版本。
- 采集黑名单是在采集路径下进行排除,因此无论是文件路径模式,还是目录路径模式,其指定路径要求为采集路径的子集。
配置采集策略
- 全量采集:Loglistener 采集文件时,从文件的开头开始读。
- 增量采集:Loglistener 采集文件时,只采集文件内新增的内容。
编码模式
- UTF-8:若您的日志文件编码模式为 UTF-8, 请选择该选项。
- GBK:若您的日志文件编码模式为 GBK, 请选择该选项。
配置分隔符模式
- 将“提取模式”设置为分隔符。
- 选择分隔符,并在“日志样例”文本框中,输入日志样例,单击提取。
系统根据确定的分隔符将日志样例进行切分,并展示在抽取结果栏中,您需要为每个字段定义唯一的 key。目前,日志采集支持多种分隔符,常见的分隔符有:空格、制表符、逗号、分号、竖线,若您的日志数据所采用的分隔符是其他符号,例如:::,也可以通过自定义分词符进行解析。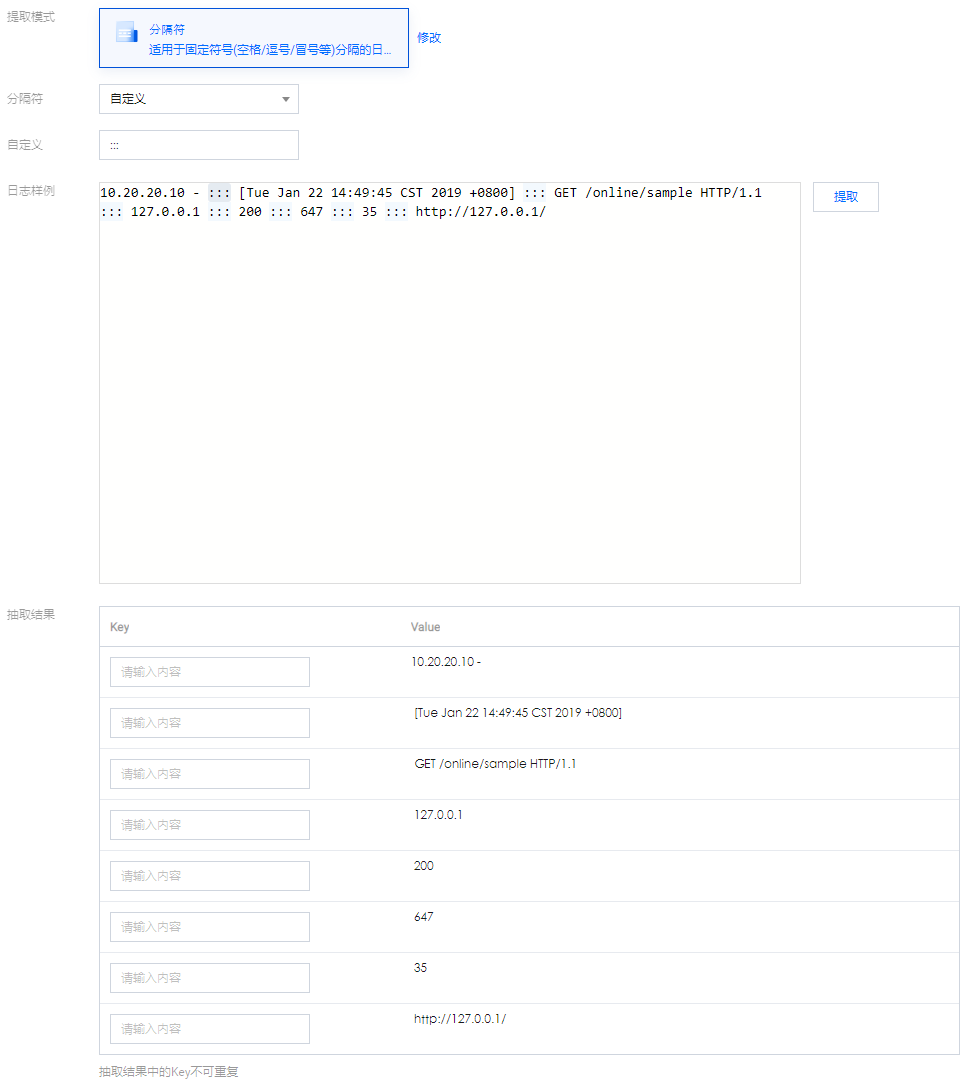

配置采集时间
- 日志时间单位为:毫秒。
- 日志的时间属性有如下方式:
- 日志采集时间:默认作为日志的时间属性。日志的时间属性由日志服务 CLS 采集该条日志的时间决定。
- 指定日志字段:填写原始时间戳的时间键以及对应的时间解析格式。日志的时间属性由原始日志中时间戳决定。
时间格式解析规则填写的示例如下:- 示例1:
日志样例原始时间戳:10/Dec/2017:08:00:00.000,解析格式为:%d/%b/%Y:%H:%M:%S.%f。 - 示例2:
日志样例原始时间戳:2017-12-10 08:00:00.000,解析格式为:%Y-%m-%d %H:%M:%S.%f。 - 示例3:
日志样例原始时间戳:12/10/2017, 08:00:00.000,解析格式为:%m/%d/%Y, %H:%M:%S.%f。
- 示例1:
注意
日志时间支持以毫秒为单位,若时间格式填写错误日志时间将以采集时间为准。
配置过滤器条件
过滤器的目的是根据业务需要添加日志采集过滤规则,以帮助您筛选出有价值的日志数据。
分隔符格式日志需要根据自定义的键值对来配置过滤条件。支持以下过滤规则:
- 等于:仅采集指定字段值匹配指定字符的日志。支持完全匹配,或正则匹配。
- 不等于:仅采集指定字段值不匹配指定字符的日志。支持完全匹配,或正则匹配。
- 字段存在:仅采集指定字段存在的日志。
- 字段不存在:仅采集指定字段不存在的日志。
例如,样例日志使用分隔符模式解析后,您希望 status 字段为400或500的所有日志数据被采集,那么 key 处配置 status,过滤规则选择等于,value 处配置400|500。注意
- 过滤规则 “不等于”、“字段存在”以及“字段不存在” 仅在 LogListener 2.9.3及以上版本支持。
- 多条过滤条件之间关系是"与"逻辑,若同一 key 名配置多条过滤条件,规则会被覆盖。
配置上传解析失败日志
建议开启上传解析失败日志。开启后,Loglistener 会上传各式解析失败的日志。若关闭上传解析失败日志,则会丢弃失败的日志。
开启后需要配置解析失败的 Key 值(默认为 LogParseFailure),所有解析失败的日志,均以输入内容作为键名称(Key),原始日志内容作为值(Value)进行上传。
高级配置
通过勾选,选择您需要定义的高级配置。
分隔符提取模式下,支持配置以下高级配置:
| 名称 | 描述 | 配置项 |
|---|---|---|
| 超时属性 | 该配置控制日志文件的超时时间。如果一个日志文件在指定时间内没有任何更新,则为超时。超时的日志文件LogListener将不再采集。当您的日志文件数量较大时,建议降低超时时间,避免LogListener性能浪费 | - 不超时:日志文件永不超时 - 自定义:自定义日志文件的超时时间 |
| 最大目录深度 | 采集路径中的/**/代表查找所有子目录中的文件。但是,在查找过程中,如果不想搜索太深的目录,可以使用"最大目录深度"配置项来限制搜索深度 | 大于0的整数。 0代表不进行子目录的下钻 |
步骤5:索引配置
- 单击下一步,进入索引配置页面。
- 在索引配置页面,设置如下信息。
索引状态:确认是否开启。
注意
检索必须开启索引配置,否则无法检索。
全文索引:确认是否需要设置大小写敏感。
全文分词符:默认为
@&?|#()='",;:<>[]{}/ \n\t\r\\,确认是否需要修改。键值索引:默认关闭,您可根据 key 名按需进行字段类型、分词符以及是否开启统计分析的配置。若您需要开启键值索引,可将
 设置为
设置为 。
。
- 单击提交,完成采集配置。
 设置为
设置为 。
。相关操作
检索日志,请参见 检索分析 文档。