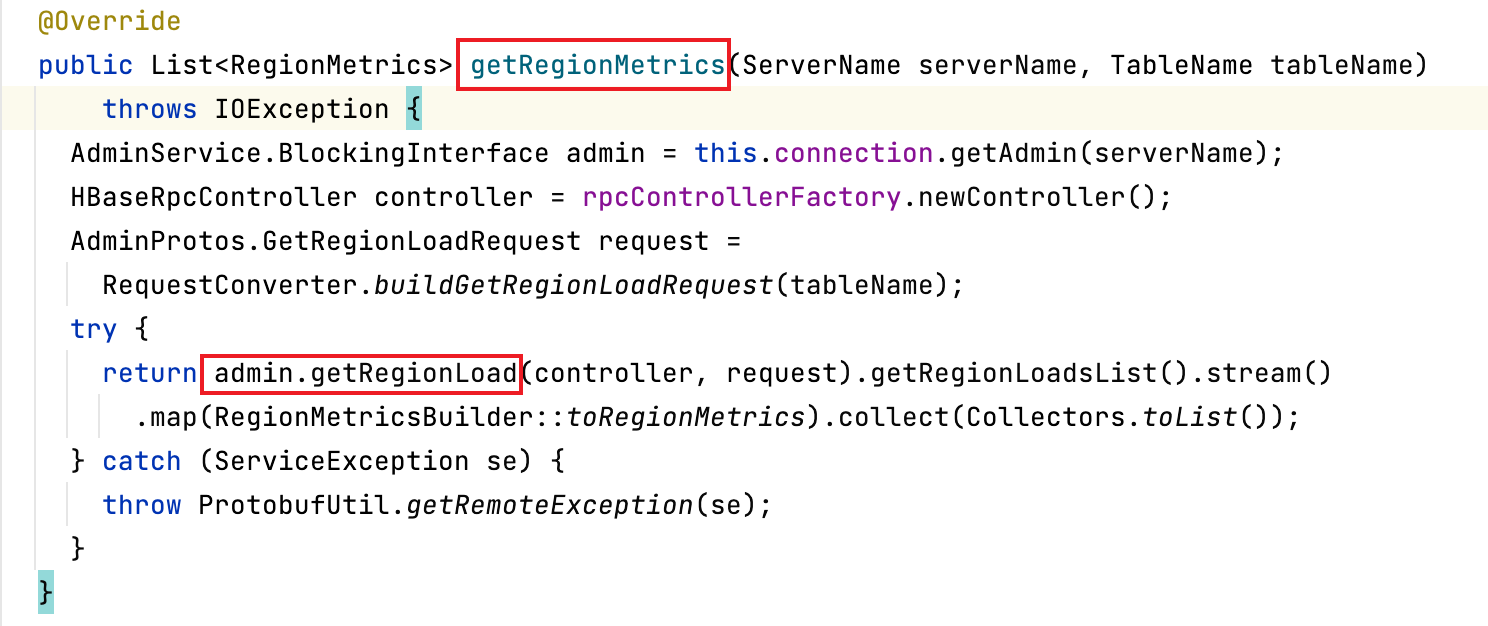
客户端访问hbase报错Connection reset by peer
Connection reset by peer是服务端主动关闭了连接。这种情况一般有以下几个原因:
- 客户端传递的认证有问题,服务端未校验通过认证信息关闭的连接,建议检查下认证信息是否设置正确。
- 客户端hbase-site.xml配置文件未正确加载。 kerberos认证过程中需要的配置项比较多,这些配置项一般在集群的
$HBASE_HOME/conf/hbase-site.xml中定义,可以尝试让应用加载到该配置文件。如果是spark应用,可以把hbase-site.xml拷贝到所有节点$SPARK_HOME/conf目录下面。
HMaster/RegionServer挂掉,频繁重启
- 可能原因
HMaster/RegionServer 分配堆内存太小,导致OOM。 - 处理方式
调大hbase-env.sh中的Heapsize和HMHeapsize
如何更改hbase表名
原生没有这个命令,可以通过快照方式绕行,这个过程中只有文件软链的生成,不会发生真实文件拷贝。
- 停止表继续插入
hbase shell>disable 'tableName'
- 制作快照
hbase shell> snapshot 'tableName', 'tableSnapshot'
- 克隆快照为新的名字
hbase shell> clone_snapshot 'tableSnapshot', 'newTableName'
- 删除快照
hbase shell> delete_snapshot 'tableSnapshot'
- 删除原来表
hbase shell> drop 'tableName'
list后即可查看到newTableName表
hbase表未上线
大量表无法上线通用处理方法
- 停掉HBase服务
- 然后移走MasterData目录 (这里不会涉及数据丢失)
hdfs dfs -mv /hbase/MasterData /hbase/MasterData2
- 启动HBase服务
- 执行
hbase hbck > hbck.txt执行健康检查命令,检查表是否都正常上线。
meta 表无法上线
- 现象
执行hbck报错,Master is initializing, 查看active master日志,有打印hbase:meta is NOT online - 处理方式
上线hbase:meta
hbase hbck -j $HBASE_HOME/hbase-hbck2/hbase-hbck2-1.2.0.jar assigns -o 1588230740
namespace表未上线
- 现象
执行hbck报错,Master is initializing, 查看active master日志,有打印hbase:namespace xxx is NOT online - 处理方式
上线hbase:namespace
hbase hbck -j $HBASE_HOME/hbase-hbck2/hbase-hbck2-1.2.0.jar assigns -o ${namespace的region id}
普通表region未上线如何处理
- 现象
执行hbck后,打印输出中有一些ERROR报错信息:region not deployed on any region server - 处理方式
单个region:
hbase hbck -j /usr/local/service/hbase/hbase-hbck2/hbase-hbck2-*.jar assigns -o ${namespace的region id}
如果有问题region数量较多,批量处理方式:
hbase hbck > hbck.txt
###下面命令有个jar包路径,可能需要根据实际路径替换
cat hbck.txt | grep Region | awk -F '\\.,' '{print $1}' | awk -F '\\.' '{print "hbase hbck -j /usr/local/service/hbase/hbase-hbck2/hbase-hbck2-*.jar assigns -o "$NF}' | grep -v ERROR > script.sh
###执行下script.sh之前检查一下再执行
chmod +x script.sh
sh script.sh
assign命令执行后仍无法上线region
- 现象
assign命令后仍然无法上线region, hbck输出还是not deployed
查看hbase UI上,对应的region处于RIT CLOSING状态。
查看Procedure & Locks页面,看到对应region有其他procedure,导致assign没有获取到锁,因此没有成功上线。 - 处理方式
需要执行以下命令将procedure lock释放,再重新执行assign命令。
hbase hbck -j $HBASE_HOME/hbase-hbck2/hbase-hbck2-1.2.0.jar bypass -or pid
访问开启kerberos认证的hbase报错GSS initiate failed
可能原因:hbase.master.kerberos.principal和hbase.regionserver.kerberos.principal配置时候不能直接配置主机名字,需要用_HOST代替,这里的principal是客户端和服务端协商使用。HMaster会主备切换,主机名不固定。
hbase支持的最大连接数是多少?
hbase不同于HiveServer,没有session的概念,所以没有固定的长连接。Hbase有并行处理线程数设置,由hbase.regionserver.handler.count(默认值64)参数控制,意味着每个RegionServer可以同时处理64个客户端请求,多余的请求会暂时被积压到callqueue队列中等待,没有直接的限制连接数量的参数,客户端连接一直增多可能会触发进程的句柄数量限制。
建议测试Regionserver每秒处理请求数比较有参考意义,测试方式:
- 设置参数,处理get请求的handler数量为3000.5(1-0.2)=120个
hbase.regionserver.handler.count=300,
hbase.ipc.server.callqueue.read.ratio=0.5
hbase.ipc.server.callqueue.scan.ratio=0.2
hbase.ipc.server.callqueue.handler.factor=0.1
hbase.ipc.server.max.callqueue.length=1000
- 停掉集群至只有1台regionserver
- 并发get查询某测试表的1条数据,查看该regionserver的Requests Per Second值。

Regionserver宕机后,重启后(运行一段时间后)自动退出
File does not exist
- 现象
存在某个(parent)Regionjava.io.FileNotFoundException: File does not exist异常: - 解决建议
执行hbase hbck检查,看看是否存在Found lingering reference file错误,有则执行hbase hbck -fixReferenceFiles修复;
存在Full GC耗时很长
- 现象
分析regionserver的GC日志(与RegionServer日志同一目录,默认在/data/emr/hbase/logs),存在Full GC耗时很长时(可能导致读写变慢),如图:

- 解决建议
修改RegionServer内存,hbase-env.sh的Heapsize的大小。


启动报某个协处理器coprocessor类找不到时,RegionServer会退出
- 分析看看是否是业务自行添加的
- 修改或添加hbase-site参数跳过coprocessor异常:
hbase.coprocessor.abortonerror=false - 启动RegionServer
存在wal.FSHLog: Slow sync cost告警,发现写WALs慢,可以配置MultiWAL特性增加并行度
- 修改hbase-site中配置
hbase.wal.provider=multiwal - 重启RegionServer服务
kerberos hbase客户端调用需要的最小配置集合是什么
需要以下配置项,具体值可以在HMaster节点的$HBASE_HOME/conf/hbase-site.xml中获取。
"hbase.zookeeper.quorum": "xx1.com,xx2.com,xx3.com",
"zookeeper.znode.parent": "/hbase-secure",
"hadoop.security.authentication":"kerberos",
"hbase.security.authentication" :"kerberos",
"hbase.master.kerberos.principal": "xx",
"hbase.regionserver.kerberos.principal": "xx",
选加:
hbase.client.keytab.principal
hbase.client.keytab.file
hbase shell 如何手动覆盖某个配置
可以通过传递或覆盖hbase-*.xml中指定的hbase配置。 在命令行上以-D为前缀的键/值,如下所示:
hbase shell -Dhbase.xxx=xxxx -Dhbase.xxx2=xxxx2
进入shell之后获取配置
@shell.hbase.configuration.get("hbase.zookeeper.quorum")
如何清空HBase 集群的数据
如果新部署未投产的集群发生了故障,这种时候可以通过清空数据来快速解决掉故障。
- 停掉HBase服务
- 删除 /hbase
hdfs dfs -mv /hbase /tmp - zkcli进入zk客户端之后,删除znode
deleteall /hbase-{id} - 启动HBase集群
其他:
如果开启了kerberos的集群,连接zk时需要认证。
${KEYTAB_PATH} 是服务器keytab的存储路径
${PRINCIPAL} 是使用klist列出的principal
klist -kt ${KEYTAB_PAH}
kinit -kt ${KEYTAB_PAH} ${PRINCIPAL}
连接zk服务端:
${ZOOKEEPER_HOME}/bin/zkCli.sh -server ${zk ip}:2181
snapshot报错Protocol message was too large
- 现象
报错:Protocol message was too large. May be malicious. Use CodedInputStream.setSizeLimit() to increase the size limit. - 可能原因
表数据量很大,HFile很多导致生成的快照信息过大,在校验snapshot信息的时候超过了Protobuf默认的大小64MB。 - 解决方案
- 建议在业务空闲时间段,通过major_compact命令分批合并表的region,文件数量减少后该问题就可以解决。
- 直接报错可以通过在hbase-site中增加参数
snapshot.manifest.size.limit=268435456(256MB), 然后重启HMaster解决 - 然后可能会遇到snapshot超时的报错,需要增加参数,然后重启HMaster解决
hbase.snapshot.master.timeout.millis=1800000(30分钟)
如何查看major compaction进度
如果有个超大的region,做了major_compact ${region id}之后不知道进展。
解决方案:
可以在hbase master ui上面看到对应的表的compaction状态是Major。
- 然后在后台可以看到对应region的.tmp目录大小一直在增长,compaction合并之后的HFile放在这里了,可以根据增长速度估计进度。
- RegionServer有个接口可以获取要处理多少KV,已经处理了多少KV,写程序获取。