
Hive on Spark任务
set hive.execution.engine=spark;
create database if not exists hive_db_spark;
use hive_db_spark;
drop table hive_table_spark;
create table hive_table_spark (id int, name string, age int) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
insert into hive_table_spark values(1,'gtc',25),(2,'tom',35),(3,'danny',24),(4,'hive',26),(5,'test',24);
select * from hive_table_spark;
任务执行过程图
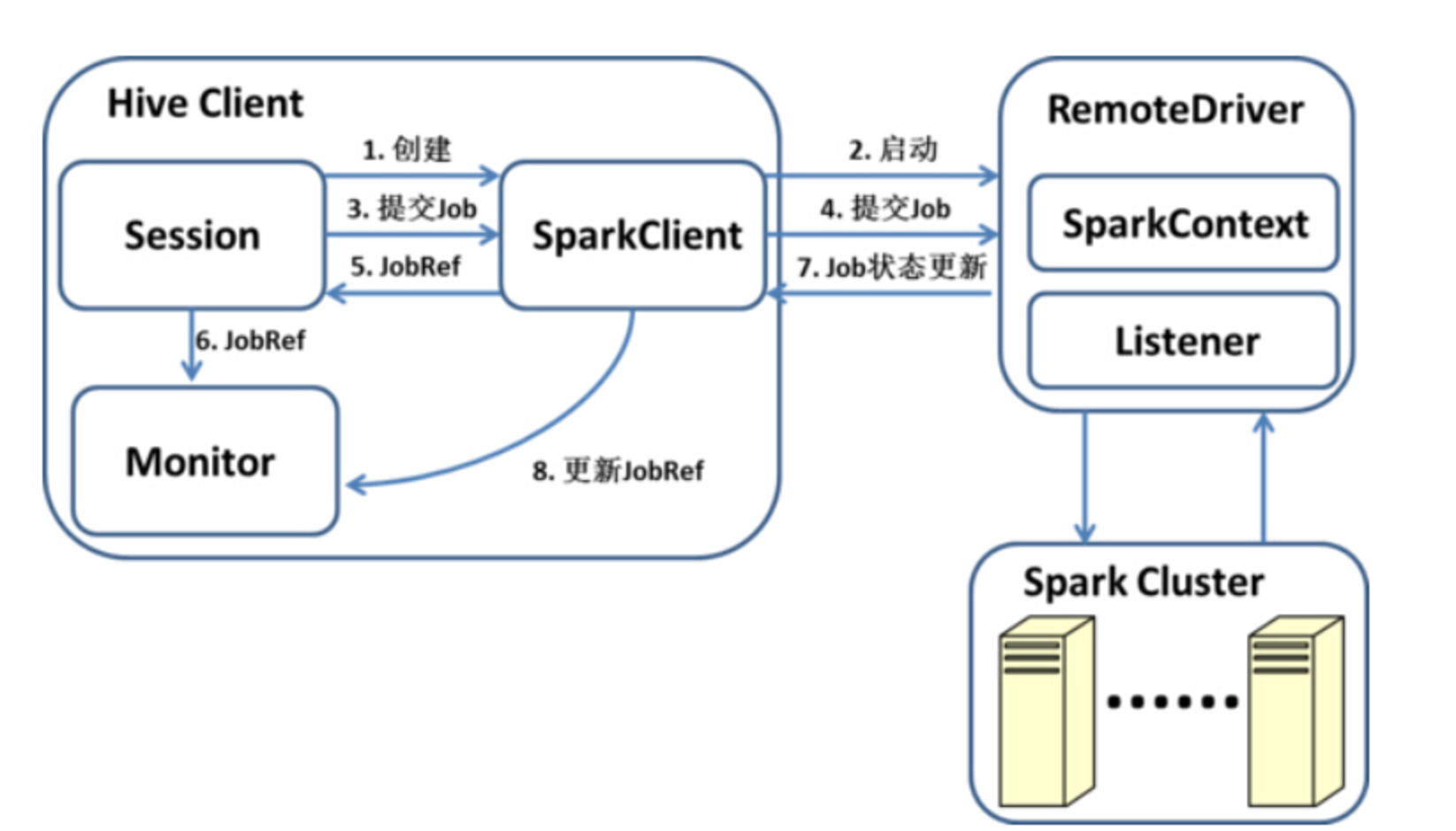
- 用户的每个Session会创建一个SparkClient,SparkClient会启动RemoteDriver进程,并由RemoteDriver创 建SparkContext。SparkTask执行时,通过Session提交任务,任务的主体就是对应的SparkWork。
- SparkClient 将任务提交给RemoteDriver,并返回一个SparkJobRef,通过该SparkJobRef,客户端可以监控任务执行进度,进行错误处理, 以及采集统计信息等。由于最终的RDD计算没有返回结果,因此客户端只需要监控执行进度而不需要处理返回值。
- RemoteDriver通过 SparkListener收集任务级别的统计数据,通过Accumulator收集Operator级别的统计数据(Accumulator被包装为 SparkCounter),并在任务结束时返回给SparkClient。
- SparkClient 与RemoteDriver之间通过基于Netty的RPC进行通信。除了提交任务,SparkClient还提供了诸如添加JAR包、获取集群信息等接口。如果客户端需要使用更一般的SparkContext的功能,可以自定义一个任务并通过SparkClient发送到RemoteDriver上执行
- Hive on Spark对于Spark集群的部署方式没有特别的要求,RemoteDriver可以连接到任意的Spark集群来执行任务。在我们的测试中,Hive on Spark在Standalone和Spark on YARN的集群上都能正常工作。

常见任务类型
Hive on MR任务
set hive.execution.engine=mr;
create database if not exists hive_db_mr;
use hive_db_mr;
drop table hive_table_mr;
create table hive_table_mr (id int, name string, age int) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
insert into hive_table_mr values(1,'gtc',25),(2,'tom',35),(3,'danny',24),(4,'hive',26),(5,'test',24);
select * from hive_table_mr;
任务执行过程图

Reduce过程分为三个不同步骤:Copy、Sort(实际应当称为Merge)及Reduce。在Copy过程中,Reducer尝试从NodeManagers获取Maps的输出并存储在内存或硬盘中。紧接着进行Shuffle过程(包含Sort及Reduce),这个过程将获取到的Maps输出进行存储并有序地合并然后提供给Reducer。当Job有大量的Maps输出需要处理的时候,Shuffle过程将变得非常耗时。对于一些特定的任务(例如hash join或hash aggregation类型的SQL任务),Shuffle过程中的排序并非必需的。但是Shuffle却默认必须进行排序,所以需要对此处进行改进。
Hive Join数据优化
操作场景
使用Join语句时,如果数据量大,可能造成命令执行速度和查询速度慢,此时可进行Join优化。
Join优化可分为以下方式:
- Map Join
- Sort Merge Bucket Map Join
- Join顺序优化
Map Join
Hive的Map Join适用于能够在内存中存放下的小表(指表大小小于25MB),通过“hive.mapjoin.smalltable.filesize”定义小表的大小,默认为25MB。
Map Join的方法有两种:
- 使用/*+ MAPJOIN(join_table) */。
- 执行语句前设置如下参数,当前版本中该值默认为“true”。set hive.auto.convert.join=true;
使用Map Join时没有Reduce任务,而是在Map任务前起了一个MapReduce Local Task,这个Task通过TableScan读取小表内容到本机,在本机以HashTable的形式保存并写入硬盘上传到HDFS,并在Distributed Cache中保存,在Map Task中从本地磁盘或者Distributed Cache中读取小表内容直接与大表join得到结果并输出。
使用Map Join时需要注意小表不能过大,如果小表将内存基本用尽,会使整个系统性能下降甚至出现内存溢出的异常。
Sort Merge Bucket Map Join
使用Sort Merge Bucket Map Join必须满足以下2个条件:
- join的两张表都很大,内存中无法存放。
- 两张表都按照join key进行分桶(clustered by (column))和排序(sorted by(column)),且两张表的分桶数正好是倍数关系。
通过如下设置,启用Sort Merge Bucket Map Join:
set hive.optimize.bucketmapjoin=true;
set hive.optimize.bucketmapjoin.sortedmerge=true;
这种Map Join也没有Reduce任务,是在Map任务前启动MapReduce Local Task,将小表内容按桶读取到本地,在本机保存多个桶的HashTable备份并写入HDFS,并保存在Distributed Cache中,在Map Task中从本地磁盘或者Distributed Cache中按桶一个一个读取小表内容,然后与大表做匹配直接得到结果并输出。
Join顺序优化
当有3张及以上的表进行Join时,选择不同的Join顺序,执行时间存在较大差异。使用恰当的Join顺序可以有效缩短任务执行时间。
Join顺序原则:
- Join出来结果较小的组合,例如表数据量小或两张表Join后产生结果较少,优先执行。
- Join出来结果大的组合,例如表数据量大或两张表Join后产生结果较多,在后面执行。
例如,customer表的数据量最多,orders表和lineitem表优先Join可获得较少的中间结果。
原有的Join语句如下:
select
l_orderkey,
sum(l_extendedprice * (1 - l_discount)) as revenue,
o_orderdate,
o_shippriority
from
customer,
orders,
lineitem
where
c_mktsegment = 'BUILDING'
and c_custkey = o_custkey
and l_orderkey = o_orderkey
and o_orderdate < '1995-03-22'
and l_shipdate > '1995-03-22'
limit 10;
Join顺序优化后如下:
select
l_orderkey,
sum(l_extendedprice * (1 - l_discount)) as revenue,
o_orderdate,
o_shippriority
from
orders,
lineitem,
customer
where
c_mktsegment = 'BUILDING'
and c_custkey = o_custkey
and l_orderkey = o_orderkey
and o_orderdate < '1995-03-22'
and l_shipdate > '1995-03-22'
limit 10;
注意事项
- Join数据倾斜问题。执行任务的时候,任务进度长时间维持在99%,这种现象叫数据倾斜。
- 数据倾斜是经常存在的,因为有少量的Reduce任务分配到的数据量和其他Reduce差异过大,导致大部分Reduce都已完成任务,但少量Reduce任务还没完成的情况。
- 解决数据倾斜的问题,可通过设置“set hive.optimize.skewjoin=true”并调整“hive.skewjoin.key”的大小。“hive.skewjoin.key”是指Reduce端接收到多少个key即认为数据是倾斜的,并自动分发到多个Reduce。
Hive Group By语句优化
操作场景
优化Group by语句,可提升命令执行速度和查询速度。
Group by的时候, Map端会先进行分组, 分组完后分发到Reduce端, Reduce端再进行分组。可采用Map端聚合的方式来进行Group by优化,开启Map端初步聚合,减少Map的输出数据量。
操作步骤
在Hive客户端进行如下设置:
set hive.map.aggr=true;
注意事项
- Group By数据倾斜Group By也同样存在数据倾斜的问题,设置“hive.groupby.skewindata”为“true”,生成的查询计划会有两个MapReduce Job,第一个Job的Map输出结果会随机的分布到Reduce中,每个Reduce做聚合操作,并输出结果,这样的处理会使相同的Group By Key可能被分发到不同的Reduce中,从而达到负载均衡,第二个Job再根据预处理的结果将Group By Key分发给Reduce任务,以完成最终的聚合操作。
- Count Distinct聚合问题当使用聚合函数count distinct完成去重计数时,处理值为空的情况会使Reduce产生很严重的数据倾斜,可以将空值单独处理,如果是计算count distinct,可以通过where子句将该值排除掉,并在最后的count distinct结果中加1。如果还有其他计算,可以先将值为空的记录单独处理,再和其他计算结果合并。