
Spark Structured Streaming
本教程演示的是:在 Kerberos 环境下,TBDS 集群运行 Spark Structured Streaming 作业来消费 Kafka 数据,实现统计单词个数,需要提前在集群中创建 Kafka Topic。更多说明请查看示例工程 README.md。
准备应用程序
- 参考【Spark 示例工程开发】,下载样例代码,选择对应迭代分支,将示例工程进行编译打包。
- 在 SparkStructuredKafkaWordCountJavaExample 示例工程中,通过使用 Spark Structured Streaming 调用 Kafka 接口来获取单词记录,然后把单词记录分类统计,最后输出每个单词的记录数。
// 创建SparkSession
SparkSession spark = SparkSession
.builder()
.appName("JavaStructuredKafkaWordCount")
.getOrCreate();
// 创建DataSet,表示从Kafka接收到的输入行流
Dataset<String> lines = spark
.readStream()
.format("kafka")
.option("kafka.bootstrap.servers", bootstrapServers)
.option(subscribeType, topics)
// 设置kafka kerberos认证(如有必要)
.option("kafka.security.protocol", "SASL_PLAINTEXT")
.option("kafka.sasl.mechanism", "GSSAPI")
.option("kafka.sasl.kerberos.service.name", "hadoop")
.load()
.selectExpr("CAST(value AS STRING)")
.as(Encoders.STRING());
// 生成运行中的单词计数
Dataset<Row> wordCounts = lines.flatMap(
(FlatMapFunction<String, String>) x -> Arrays.asList(x.split(" ")).iterator(),
Encoders.STRING()).groupBy("value").count();
// 开始运行查询,该查询将运行中的单词计数打印到控制台
StreamingQuery query = wordCounts.writeStream()
.outputMode("complete")
.format("console")
.start();
query.awaitTermination();
运行 Spark Structured Streaming 作业
- 准备主题:创建一个名为 spark_structured_streaming_topic 的 topic。
- 准备用户:获取用户认证信息,需要将用户的 keytab 文件下载到本地,然后上传至开发机。这里将 test 用户的 test.keytab 文件上传至开发机的 /tmp 目录,并进行 kerberos 认证。
# Kerberos认证
[test@10 ~]$ klist -kt /tmp/test.keytab
Keytab name: FILE:/tmp/test.keytab
KVNO Timestamp Principal
---- ------------------- ------------------------------------------------------
1 11/28/2024 22:05:22 test@TBDS-JYOKXQY8
1 11/28/2024 22:05:22 test@TBDS-JYOKXQY8
[test@10 ~]$ kinit -kt /tmp/test.keytab test@TBDS-JYOKXQY8
- Ranger 授权:确保 test 用户具有提交 yarn default 队列的权限。
- 运行样例:将编译后的 jar 包上传到开发机 /tmp 目录,进入 Spark 安装目录,一般位于 /usr/local/service/spark,然后使用 spark-submit 命令提交,根据需要选择 Cluster 模式或 Client 模式。若项目依赖第三方 Jar,可以通过 --jars 参数进行指定。
- Cluster 模式提交:应用程序参数依次为:brokers、subscribe-type、topics,具体说明如下。等 Spark Structured Streaming 任务正常运行起来后,使用 Kafka 客户端同时向 spark_structured_streaming_topic 生产一些数据。
- brokers:即 Kafka 配置 bootstrap.servers,host:port 之间使用逗号分隔。
- subscribe-type:有三种类型,Kafka 源只能指定 assign、subscribe 或 subscribePattern 中的一个。其中 assign 指定要消费的 TopicPartitions,值为 JSON 字符串,例如 {"topicA":[0,1],"topicB":[2,4]}。subscribe 指定要订阅的 Topic,值为逗号分隔的 Topic 列表。 subscribePattern 指定订阅 Topic 的模式,值为 Java 正则表达式字符串。
- topics:根据 subscribe-type 的值,采用不同的格式。
# 1. 准备sasl认证配置文件,内容如下,编辑后保存退出
[test@10 ~]$ vim /tmp/kafka_jaas.conf
KafkaClient {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
storeKey=true
keyTab="./test.keytab"
principal="test@TBDS-JYOKXQY8";
};
# 2. 以Cluster模式提交Spark Structured Streaming任务,参数依次为:brokers、subscribe-type、topics
[test@10 ~]$ /usr/local/service/spark/bin/spark-submit \
--master yarn \
--deploy-mode cluster \
--files /tmp/kafka_jaas.conf,/tmp/test.keytab,/etc/krb5.conf \
--conf spark.driver.extraJavaOptions="-Djava.security.auth.login.config=./kafka_jaas.conf -Djava.security.krb5.conf=./krb5.conf" \
--conf spark.executor.extraJavaOptions="-Djava.security.auth.login.config=./kafka_jaas.conf" \
--class com.tencent.tbds.spark.SparkStructuredKafkaWordCountJavaExample \
SparkStructuredKafkaWordCountJavaExample-1.0.jar \
broker1:9092,broker2:9092,broker3:9092 subscribe spark_structured_streaming_topic

6. Client 模式提交:Driver sasl 认证配置文件 kafka_driver_jaas.conf(由 Yarn 客户端使用)和 kafka_jaas.conf 基本相同,除了 keyTab 处有一些差异。在 kafka_driver_jaas.conf 中,keyTab 应为 {keytab_path}/kafka.service.keytab。
# 1. 准备driver sasl认证配置文件,内容如下(KafkaClient用于Kafka认证,Client使用ZK认证),编辑后保存退出
[test@10 ~]$ vim /tmp/kafka_driver_jaas.conf
KafkaClient {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
storeKey=true
keyTab="/tmp/test.keytab"
principal="test@TBDS-JYOKXQY8";
};
Client {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
storeKey=true
keyTab="/tmp/test.keytab"
principal="test@TBDS-JYOKXQY8";
};
# 2. Client模式提交Spark Structured Streaming任务,参数依次为:brokers、subscribe-type、topics
[test@10 ~]$ /usr/local/service/spark/bin/spark-submit \
--master yarn \
--deploy-mode client \
--files /tmp/kafka_jaas.conf,/tmp/test.keytab \
--conf spark.driver.extraJavaOptions="-Djava.security.auth.login.config=/tmp/kafka_driver_jaas.conf" \
--conf spark.executor.extraJavaOptions="-Djava.security.auth.login.config=./kafka_jaas.conf" \
--class com.tencent.tbds.spark.SparkStructuredKafkaWordCountJavaExample \
SparkStructuredKafkaWordCountJavaExample-1.0.jar \
broker1:9092,broker2:9092,broker3:9092 subscribe spark_structured_streaming_topic

Spark Streaming
本教程演示的是:在 Kerberos 环境下,TBDS 集群运行 Spark Streaming 作业来消费 Kafka 数据,实现统计单词个数,需要提前在集群中创建 Kafka Topic。更多说明请查看示例工程 README.md。
注:Spark Streaming 是 Spark 的上一代流处理引擎,Spark Streaming 已经不再更新,它是一个遗留项目。在 Spark 中有一个更新且更易于使用的流处理引擎,叫做 Structured Streaming,建议在流式应用中使用 Spark Structured Streaming,具体可以参考 Structured Streaming 编程指南。
2.1 准备应用程序
- 参考【Spark 示例工程开发】,下载样例代码,选择对应迭代分支,将示例工程进行编译打包。
- 在 SparkDirectKafkaWordCountJavaExample 示例工程中,通过使用 Spark Streaming 调用 Kafka 接口来获取单词记录,然后把单词记录分类统计,最后输出每个单词的记录数。
// 创建2秒批处理间隔的上下文
SparkConf sparkConf = new SparkConf().setAppName("SparkDirectKafkaWordCountJavaExample");
JavaStreamingContext jssc = new JavaStreamingContext(sparkConf, Durations.seconds(5));
Set<String> topicsSet = new HashSet<>(Arrays.asList(topics.split(",")));
Map<String, Object> kafkaParams = new HashMap<>();
kafkaParams.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers);
kafkaParams.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
kafkaParams.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
kafkaParams.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
// 设置kafka kerberos认证(如有必要)
kafkaParams.put("security.protocol", "SASL_PLAINTEXT");
kafkaParams.put("sasl.mechanism", "GSSAPI");
kafkaParams.put("sasl.kerberos.service.name", "hadoop");
// 使用brokers和topics创建direct kafka stream
JavaInputDStream<ConsumerRecord<String, String>> messages = KafkaUtils.createDirectStream(
jssc,
LocationStrategies.PreferConsistent(),
ConsumerStrategies.Subscribe(topicsSet, kafkaParams));
// 获取行,将其拆分为单词,计算单词数并打印
JavaDStream<String> lines = messages.map(ConsumerRecord::value);
JavaDStream<String> words = lines.flatMap(x -> Arrays.asList(SPACE.split(x)).iterator());
JavaPairDStream<String, Integer> wordCounts = words.mapToPair(s -> new Tuple2<>(s, 1))
.reduceByKey((i1, i2) -> i1 + i2);
wordCounts.print();
// 开始计算
jssc.start();
jssc.awaitTermination();
2.2 运行 Spark Streaming 作业
- 参考【Kafka 常用命令】,在 TBDS 集群创建一个名为 spark_streaming_topic 的 topic。
- 准备用户:获取用户认证信息,需要将用户的 keytab 文件下载到本地,然后上传至开发机。这里将 test 用户的 test.keytab 文件上传至开发机的 /tmp 目录,并进行 kerberos 认证。
# Kerberos认证
[test@10 ~]$ klist -kt /tmp/test.keytab
Keytab name: FILE:/tmp/test.keytab
KVNO Timestamp Principal
---- ------------------- ------------------------------------------------------
1 11/28/2024 22:05:22 test@TBDS-JYOKXQY8
1 11/28/2024 22:05:22 test@TBDS-JYOKXQY8
[test@10 ~]$ kinit -kt /tmp/test.keytab test@TBDS-JYOKXQY8
- Ranger 授权:确保 test 用户具有提交 yarn default 队列的权限。
- 运行样例:将该 jar 包上传到开发机 /tmp 目录,进入 Spark 安装目录,一般位于 /usr/local/service/spark,然后使用 spark-submit 命令提交,根据需要选择 Cluster 模式或 Client 模式。若项目依赖第三方 JAR,可以通过 --jars 参数进行指定,更多参数说明参考【Spark 常用命令】。
- Cluster 模式提交:等 Spark Streaming 任务正常运行起来后,使用 Kafka 客户端同时向 spark_streaming_topic 生产一些数据,参考【Kafka 常用命令】。注意,应用程序参数依次为:brokers、groupId、topic。
# 1. 准备sasl认证配置文件,内容如下,编辑后保存退出
[test@10 ~]$ vim /tmp/kafka_jaas.conf
KafkaClient {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
storeKey=true
keyTab="./test.keytab"
principal="test@TBDS-JYOKXQY8";
};
# 2. 以Cluster模式提交Spark Streaming任务,参数依次为:brokers、groupId、topic
[test@10 ~]$ /usr/local/service/spark/bin/spark-submit \
--master yarn \
--deploy-mode cluster \
--files /tmp/kafka_jaas.conf,/tmp/test.keytab,/etc/krb5.conf \
--conf spark.driver.extraJavaOptions="-Djava.security.auth.login.config=./kafka_jaas.conf -Djava.security.krb5.conf=./krb5.conf" \
--conf spark.executor.extraJavaOptions="-Djava.security.auth.login.config=./kafka_jaas.conf" \
--class com.tencent.tbds.spark.SparkDirectKafkaWordCountJavaExample \
SparkDirectKafkaWordCountJavaExample-1.0.jar \
broker1:9092,broker2:9092,broker3:9092 tmp_group spark_streaming_topic
- YARN UI 页面根据 ApplicationID、User、Name 等信息,查看对应的 Spark 任务日志。可以看到,任务日志中有输出单词统计相关信息,如下图所示。
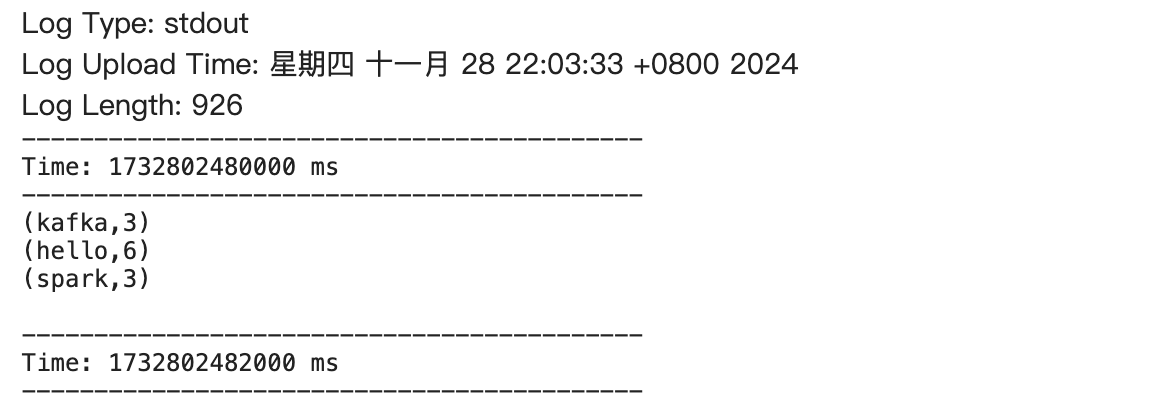
- Client 模式提交:注意,Driver sasl 认证配置文件 kafka_driver_jaas.conf(由 Yarn 客户端使用)和 kafka_jaas.conf 基本相同,除了 'keyTab' 处有一些差异。在 kafka_driver_jaas.conf 中,'keyTab' 应为“{keytab_path}/kafka.service.keytab”。

# 1. 准备driver sasl认证配置文件,内容如下(KafkaClient用于Kafka认证,Client使用ZK认证),编辑后保存退出
[test@10 ~]$ vim /tmp/kafka_driver_jaas.conf
KafkaClient {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
storeKey=true
keyTab="/tmp/test.keytab"
principal="test@TBDS-JYOKXQY8";
};
Client {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
storeKey=true
keyTab="/tmp/test.keytab"
principal="test@TBDS-JYOKXQY8";
};
# 2. Client模式提交Spark Streaming任务,参数依次为:brokers、groupId、topic
[test@10 ~]$ /usr/local/service/spark/bin/spark-submit \
--master yarn \
--deploy-mode client \
--files /tmp/kafka_jaas.conf,/tmp/test.keytab \
--conf spark.driver.extraJavaOptions="-Djava.security.auth.login.config=/tmp/kafka_driver_jaas.conf" \
--conf spark.executor.extraJavaOptions="-Djava.security.auth.login.config=./kafka_jaas.conf" \
--class com.tencent.tbds.spark.SparkDirectKafkaWordCountJavaExample \
SparkDirectKafkaWordCountJavaExample-1.0.jar \
broker1:9092,broker2:9092,broker3:9092 tmp_group spark_streaming_topic
- 不同于 Cluster 模式,单词统计相关信息将直接输出在控制台,如下图所示。
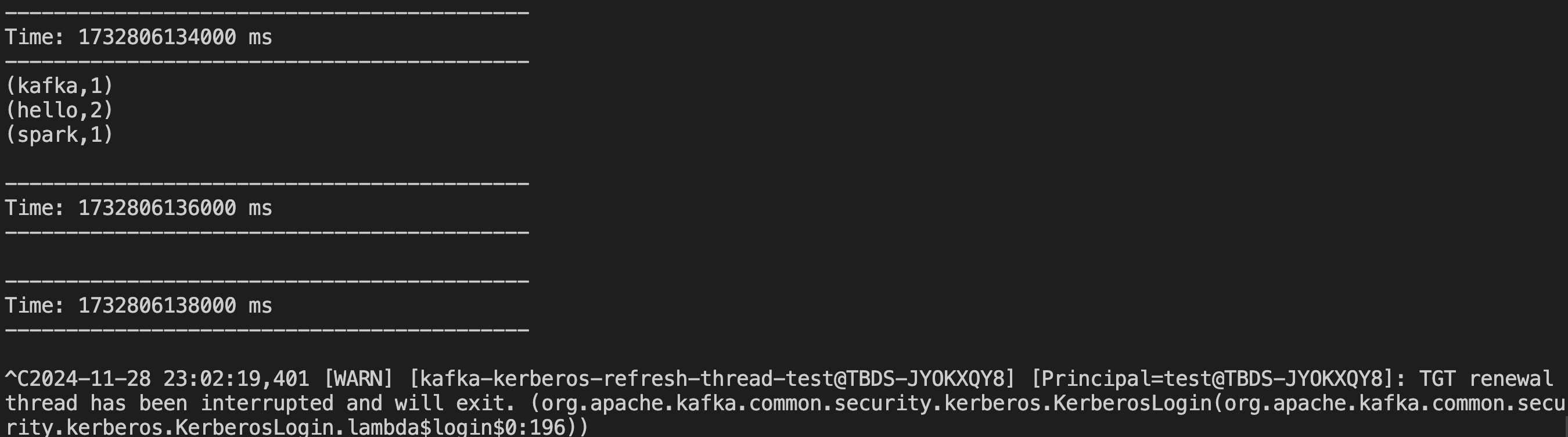

3. Spark SQL
本教程演示的是:Spark Hive SQL 任务,需要提前将示例工程 resources 目录下的 kv1.txt 文件放至 HDFS。更多说明请查看示例工程 README.md。
3.1 准备应用程序
- 参考【Spark 示例工程开发】,下载样例代码,选择对应迭代分支,将示例工程进行编译打包。
- 在 SparkHiveJavaExample 示例工程中,首先创建了一张 Hive 表,并从 HDFS 中加载数据;然后进行基本查询和聚合查询;最后通过 DataFrame 访问每列数据,并创建临时视图。
// 初始化SparkSession, 并开启Hive支持
SparkSession spark = SparkSession
.builder()
.appName("Spark Hive Java Example")
.enableHiveSupport()
.getOrCreate();
// 创建Hive表
spark.sql("CREATE TABLE IF NOT EXISTS tmp_src (key INT, value STRING) USING hive");
// 从HDFS加载数据
spark.sql("LOAD DATA INPATH '" + args[0] + "' INTO TABLE tmp_src");
// 基本查询
spark.sql("SELECT * FROM tmp_src").show();
// 聚合查询
spark.sql("SELECT COUNT(*) FROM tmp_src").show();
// SQL查询结果类型是Dataset<Row>,即DataFrame,并且支持所有常规函数
Dataset<Row> sqlDF = spark.sql("SELECT key, value FROM tmp_src WHERE key < 10 ORDER BY key");
// DataFrame中的每个元素都是Row类型,可以通过序号访问每列
Dataset<String> stringsDS = sqlDF.map(
(MapFunction<Row, String>) row -> "Key: " + row.get(0) + ", Value: " + row.get(1),
Encoders.STRING());
stringsDS.show();
// 可以使用DataFrame在SparkSession中创建临时视图
List<Record> records = new ArrayList<>();
for (int key = 1; key < 100; key++) {
Record record = new Record();
record.setKey(key);
record.setValue("val_" + key);
records.add(record);
}
Dataset<Row> recordsDF = spark.createDataFrame(records, Record.class);
recordsDF.createOrReplaceTempView("tmp_records");
// 可以将DataFrame的数据与存储在Hive中的数据进行join
spark.sql("SELECT * FROM tmp_records r JOIN tmp_src s ON r.key = s.key").show();
// 关闭SparkSession
spark.stop();
3.2 运行 Spark SQL 作业
- 准备用户:获取用户认证信息,需要将用户的 keytab 文件下载到本地,然后上传至开发机。这里将 test 用户的 test.keytab 文件上传至开发机的 /tmp 目录,并进行 kerberos 认证。
- 准备文件:将 resources 目录下的 kv1.txt 文件上传至开发机 /tmp 目录,然后将其上传至 HDFS /tmp 目录。
# 1. Kerberos认证(Simple认证跳过该步)
[test@10 ~]$ klist -kt /tmp/test.keytab
Keytab name: FILE:/tmp/test.keytab
KVNO Timestamp Principal
---- ------------------- ------------------------------------------------------
1 11/28/2024 22:05:22 test@TBDS-JYOKXQY8
1 11/28/2024 22:05:22 test@TBDS-JYOKXQY8
[test@10 ~]$ kinit -kt /tmp/test.keytab test@TBDS-JYOKXQY8
# 2.上传kv1.txt文件至HDFS
[test@10 ~]$ /usr/local/service/hadoop/bin/hdfs dfs -put /tmp/kv1.txt /tmp
- Ranger 授权:确保 test 用户具有提交 yarn default 队列的权限。
- 运行样例:将编译后的 jar 包上传到开发机 /tmp 目录,进入 Spark 安装目录,一般位于 /usr/local/service/spark,然后使用 spark-submit 命令提交,根据需要选择 Cluster 模式或 Client 模式。若项目依赖第三方 Jar,可以通过 --jars 参数进行指定。
[test@10 ~]$ cd /usr/local/service/spark
[test@10 spark]$ bin/spark-submit \
--master yarn \
--deploy-mode client \
--queue default \
--keytab /tmp/test.keytab \
--principal test@TBDS-JYOKXQY8 \
--class com.tencent.tbds.spark.SparkHiveJavaExample \
/tmp/SparkHiveJavaExample-1.0.jar hdfs:///tmp/kv1.txt