
RDD
利用缓存复用RDD
RDD 中的数据只会在计算中产生,在计算完成后就会消失,这意味着对同一个 RDD 执行算子操作时,都需要从头开始计算。可以使用 persist() 或 cache() 函数将 RDD 缓存在内存或磁盘中,以便在后续的计算中复用,这使得后面的操作速度大大加快(通常快 10 倍以上)。
Spark 缓存级别如下表所示。注意:在 Python 中,存储对象总是被 pickle 库序列化,所以是否选择序列化级别并不重要。
| 缓存级别 | 含义 |
|---|---|
| MEMORY_ONLY | 在JVM中将RDD存储为反序列化的Java对象。如果内存中没有足够的RDD,某些分区将不会被缓存,而是在每次需要时重新计算。这是默认级别,cache() 函数使用的就是这种缓存策略。 |
| MEMORY_AND_DISK | 在JVM中将RDD存储为反序列化的Java对象。如果内存中容纳不下RDD,则将容纳不下的部分存储在磁盘上,需要时从磁盘上读取。 |
| MEMORY_ONLY_SER (Java and Scala) |
将RDD存储为序列化的Java对象(每个分区一个字节数组)。这通常比反序列化对象更节省空间,特别是在使用快速序列化器时,但读取时更耗费CPU。 |
| MEMORY_AND_DISK_SER (Java and Scala) |
类似于MEMORY_ONLY_SER,但是将内存中无法容纳的分区溢出到磁盘,而不是在每次需要时重新计算。 |
| DISK_ONLY | 仅在磁盘上存储 RDD 分区。 |
| MEMORY_ONLY_2, MEMORY_AND_DISK_2, etc. | 与上述级别相同,但在两个群集节点上复制每个分区。 |
| OFF_HEAP (experimental) | 与MEMORY_ONLY_SER类似,但将数据存储在堆外内存中。这要求启用堆外内存。 |
Spark 的存储级别是为了在内存使用和 CPU 效率之间提供不同的权衡。建议通过以下过程来选择一个:
- 如果 RDD 适合默认存储级别 MEMORY_ONLY,保持该级别。这是最节省 CPU 的选项,可使 RDD 上的操作尽可能快地运行。
- 如果不行,尝试使用 MEMORY_ONLY_SER,并选择一个快速序列化库,使对象更节省空间,但访问速度仍相当快。
- 不要溢出到磁盘,除非计算数据集的函数非常昂贵,或者过滤了大量数据。否则,重新计算一个分区可能和从磁盘读取数据一样快。
- 如果希望快速故障恢复,使用复制存储级别(例如,如果使用 Spark 来服务来自 Web 应用程序的请求)。所有存储级别都通过重新计算丢失的数据提供完全容错,但复制存储级别可让你继续在 RDD 上运行任务,而无需等待重新计算丢失的分区。
合理选择RDD算子
mapPartitions 替换 map
map 算子是分区内一个个数据的执行,类似于串行操作,所以性能较低;而 mapPartitions 算子是以分区为单位进行批处理操作,所以性能较高。但是 mapPartitions 算子会长时间占用内存,导致内存可能不够用,出现 OOM,所以在内存有限的情况下,不推荐使用,而应使用 map 操作。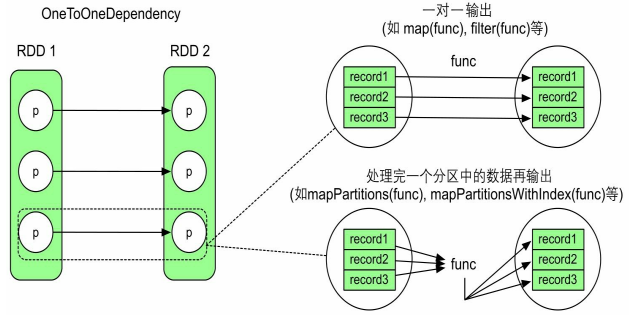
foreachPartition 替换 foreach
foreachPartition 和 foreach 的关系类似于 mapPartitions 和 map 的关系。reduceByKey/aggregateByKey 替换 groupByKey
与 groupByKey 不同,reduceByKey(func, numPartitions) 实际包含两步聚合。第一步,在 Shuffle 之前对每个分区的数据进行一个本地化的 combine() 聚合操作,也称为mini-reduce 或 map 端 combine,这一步由 Spark 自动完成,并不形成新的 RDD,减少了数据传输量和内存用量,效率比 groupByKey 高。第二步,reduceByKey 生成新的 ShuffledRDD,将来自不同分区且具有相同 key 的数据聚合在一起,利用 func 进行 reduce() 聚合操作。整个过程中,combine() 和reduce() 的计算逻辑一样,采用同一个 func。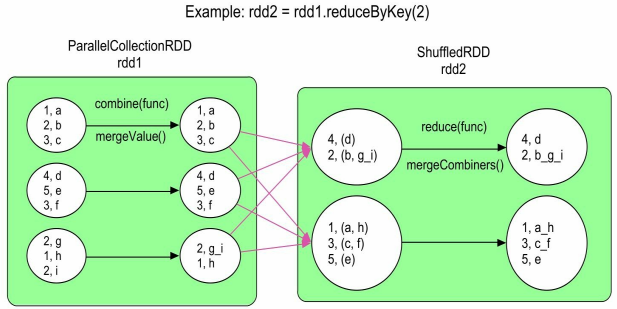
coalesce 与 repartition 重分区
两者均是将 RDD 中的数据进行重新分区,repartition(numPartitions) 语义与 coalesce(numPartitions, true) 一致(第二个参数表示是否 shuffle),即 repartition 一定会进行 shuffle。而 coalesce 将相邻的分区直接合并在一起,形成的数据依赖关系是多对一的窄依赖,不会触发数据的 shuffle。因此在不进行 shuffle 的情况下,coalesce 不能将一个分区拆分为多份,且当 RDD 中不同分区中的数据量差别较大时,直接合并容易造成数据倾斜。为了增加分区或解决数据倾斜问题,可以指定 shuffle=true 将数据打乱。
当数据集较小,而分区数量较多时,可以使用 coalesce 来减少分区数量,从而减少资源消耗和网络传输开销。例如,使用 filter 算子过滤掉 RDD 较多数据后,可以使用 coalesce 减少分区数,根据经验值,分区数一般是核心数的 2-3 倍。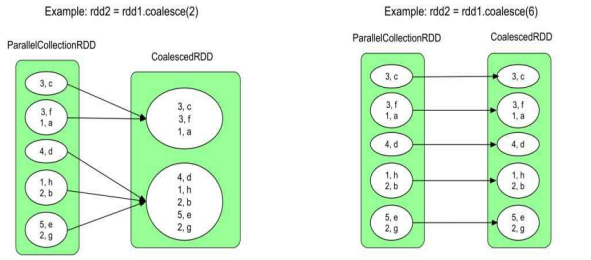
repartitionAndSortWithinPartitions 替换 repartition 与 sortByKey
repartitionAndSortWithinPartitions 可以灵活使用各种分区器,且对于结果 RDD 中的每个分区,对其中的数据按照 key 进行排序,该操作比 repartition + sortByKey 效率高,因为它可以将排序下放到 shuffle 机制中。不过由于 repartitionAndSortWithinPartitions 可定义分区器,不一定是 sortByKey 默认的 RangePartitioner,因此它得到的结果不能保证 key 全局有序。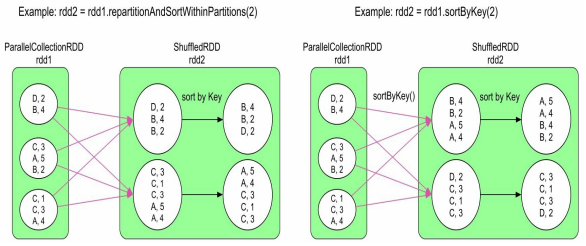




减少不必要的action算子
Spark 将数据操作分为两种,transformation 操作(转换算子)和 action 操作(行动算子),两者的区别是行动算子一般是对结果数据进行后处理,产生输出结果,且会触发 Spark 提交 job 真正执行数据处理任务。
当应用程序出现 action 操作时,表示应用会生成一个 job。如果应用程序中有很多 action 操作,那么 Spark 会按照顺序为每个 action 操作生成一个 job,每个 job 的逻辑处理流程都是从输入数据到最后 action 操作。 因此,减少不必要的 action 算子可以提高 Spark 的性能和效率。
尽量避免使用shuffle算子
Spark 作业运行过程中,最消耗性能的地方就是 shuffle。shuffle 分为 shuffle write 和 shuffle read 两个阶段,前者将 map 端的输出数据按照 key 进行分区,并将输出数据写入到本地磁盘或者网络中,后者读取 shuffle write 阶段输出的数据,并进行合并和计算,最终生成结果。由此可见,磁盘 IO 和网络数据传输是 shuffle 性能较差的主要原因。
因此,应该尽量避免使用 shuffle 算子,如 repartition、reduceByKey、join 等,尽量使用非 shuffle 类算子。
广播大变量
广播变量是一个只读变量,通过它可以将一些共享数据集或者大变量缓存在 Spark 集群中的各个机器上,而不用每个 task 都需要复制一个副本,后续计算可以重复使用,减少了数据传输时网络带宽的使用,提高效率。相比于 Hadoop 的分布式缓存,广播的内容可以跨作业共享。广播变量要求广播的数据不可变、不能太大但也不能太小(一般几十M以上)、可被序列化和反序列化、并且必须在 Driver 端声明广播变量,适用于广播多个 Stage 公用的数据,存储级别目前是 MEMORY_AND_DISK。
val rdd = sc.makeRDD(List(("a", 1), ("b", 2), ("c", 3)))
val map = mutable.Map(("a", 4), ("b", 5), ("c", 6))
// 封装广播变量,如果直接使用map,则每个Task都各自持有该变量,数据重复且占用大量内存
val bc: Broadcast[mutable.Map[String, Int]] = sc.broadcast(map)
rdd.map {
case (w, c) => {
val l: Int = bc.value.getOrElse(w, 0)
(w, (c, l))
}
}.collect().foreach(println)
使用Kryo序列化
序列化在任何分布式应用程序的性能中都起着重要作用,序列化对象速度慢或消耗大量字节的格式将大大降低计算速度。Spark 的目标是在便利性(允许在操作中使用任何 Java 类型)和性能之间取得平衡,它提供了两个序列化库:
- Java序列化:默认情况下,Spark 使用 Java 的 ObjectOutputStream 框架对对象进行序列化,并可与创建的任何实现 java.io.Serializable 的类协同工作。还可以通过扩展 java.io.Externalizable 更紧密地控制序列化的性能。Java 序列化非常灵活,但通常相当缓慢,而且会导致许多类的序列化格式过大。
- Kryo序列化:Spark 还可以使用 Kryo 库更快地序列化对象。Kryo 比 Java 序列化要快得多,也更紧凑(通常是 Java 序列化的 10 倍),但不支持所有可序列化类型,而且需要提前注册程序中使用的类,以获得最佳性能。
通过使用 SparkConf 初始化作业,并调用 conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer") 可以切换到使用 Kryo。该设置不仅可以配置在worker 节点间 shuffle 数据时使用的序列化器,还可以配置将 RDD 序列化到磁盘时使用的序列化器。Kryo 不是默认设置的唯一原因是需要自定义注册,但建议在任何网络密集型应用中尝试使用。自 Spark 2.0.0 以来,在内部使用 Kryo 序列化器来处理简单类型、简单类型数组或字符串类型的 RDD。
如果对象较大,可能还需要增加 spark.kryoserializer.buffer 配置。这个值必须足够大,以容纳你要序列化的最大对象。最后,如果你不注册自定义类,Kryo 仍然可以工作,但它必须在每个对象中存储完整的类名,这就造成了浪费。
val conf = new SparkConf().setMaster(...).setAppName(...)
// 设置序列化器为KryoSerializer
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
// 向Kryo注册自己的自定义类
conf.registerKryoClasses(Array(classOf[MyClass1], classOf[MyClass2]))
val sc = new SparkContext(conf)
优化数据结构
默认情况下,Java 对象的访问速度很快,但占用的空间却比其字段中的“原始”数据多出 2-5 倍。原因如下:
- 每个不同的 Java 对象都有一个约 16 字节的“对象头”,其中包含指向其类的指针等信息。对于数据量极少的对象(例如一个 int 字段)来说,这个头可能比数据量还大。
- Java 字符串与原始字符串数据相比有大约 40 个字节的开销(因为它们将数据存储在一个 char 数组中,并保留了额外的数据,如长度),并且由于字符串内部使用 UTF-16 编码,每个字符存储为两个字节。因此,一个 10 个字符的字符串可以轻松占用 60 个字节。
- 常见的集合类,如 HashMap 和 LinkedList,使用链接数据结构,其中每个条目都有一个“封装”对象(如 Map.Entry)。这个对象不仅有一个标头,还有指向列表中下一个对象的指针(通常每个指针 8 字节)。
- 原始类型的集合通常将它们存储为“包装”对象,如 java.lang.Integer。
减少内存消耗的第一种方法是避免使用会增加开销的 Java 特性,Spark 官方建议:
- 设计数据结构时,优先选择对象数组和原始类型,而不是标准的 Java 或 Scala 集合类(如 HashMap)。
- 尽可能避免使用包含大量小对象和指针的嵌套结构。
- 考虑使用数字 ID 或枚举对象代替字符串作为键。
Spark SQL
注意 null 的特殊性
SQL 对 null 的处理比较特殊,一些计算逻辑中经常会直接跳过 null。但用户经常将 null 当作一个具体的值,因此会出现一些困惑的情况。例如,null 既不参与 in 表达式计算,也不参与 not in 表达式计算,若数据中存在 null,则两个表达式得到的结果之和并不等于总的数据结果。
另外,需要注意过滤 key 为空字符串和 null 的情形,因为如果空字符串或 null 的记录数较多,就可能导致大量数据分配到同一个 task 执行,引起数据倾斜,进而导致任务执行时间变长。
多表 join 顺序调整
多表 join 场景中,数据表的顺序对性能影响比较大,例如,A join B join C 与 A join C join B,两者中间产生的数据量可能差别很大。实际上,多表 join 一直都是数据库中基于代价优化机制(Cost-Based Optimization,简称 CBO)的重要针对对象,如果是针对数据相对固定的表进行 SQL 查询,建议打开该配置,相关参数说明如下表所示。不过要使用该功能,需确保相关表和列的统计信息已经生成,并定期更新和维护。
| 参数 | 默认值 | 参数说明 |
|---|---|---|
| spark.sql.cbo.enabled | false | 是否启用 CBO |
| spark.sql.cbo.joinReorder.enabled | false | 在 CBO 中启用 join 重排 |
-- 生成表级别统计信息
ANALYZE TABLE 表名 COMPUTE STATISTICS
-- 生成列级别统计信息
ANALYZE TABLE 表名 COMPUTE STATISTICS FOR COLUMNS 列 1, 列 2, 列 3
-- 显示表统计信息
DESC FORMATTED 表名
-- 显示列统计信息
DESC FORMATTED 表名 列名
复用数据
数据复用的场景较多,绝大部分以 union 操作为主。如果读取同一份数据的两个任务之间没有依赖关系,可以想办法合并任务逻辑,使得只需要读取一次数据,减少 IO 代价。
-- 数据表t被读取两次,当表数据量非常大时,对性能影响大
select *
from (
select value form t where key = k1
union all
select value form t where key = k2
)
-- 优化后,只需要读取一次数据表,减少IO代价
select *
from (
select value form t where key = k1 or key = k2
)
处理数据倾斜
数据倾斜是经常碰到的一类问题,可通过以下方法来优化或规避:
- 过滤无关数据:大量的 null 数据没有过滤,参与了 join 的执行;存在“脏数据”,不满足原有的数据类型。
- 广播小表:若参与 join 操作的两个表是大小表,可以采用 BroadcastJoin 方式,即将小表广播到大表所在的 executor 上,避免数据倾斜。Spark 支持在 SQL 中通过添加 Hint 的方式强制采用 BroadcastJoin,不过需要注意,对于外连接,基表不能被广播,因此左外连接中左表不可以是小表,右外连接中右表不可以是小表。
-- 将小表t1广播到大表t2所在的Executor上
select /*+ BROADCAST(t1) */ * from t1, t2 where t1.key = t2.key
- 分离倾斜数据:假设参加 join 操作的两个表分别为 t1、t2,其中表 t1 有数据倾斜。可以将 t1 的数据分为两部分:不含倾斜数据的 t11、只包含倾斜数据的 t12。数据表 t11 和 t12 分别与 t2 进行 join 操作,然后将结果合并。首先,t11 与 t2 的 join 操作不存在数据倾斜;其次,由于 t12 通常不会很大,所以 t12 与 t2 的 join 操作可以采用第二种方法执行 BroadcastJoin。
select * from (
select * from t11, t2 where t11.key = t2.key
union all
select /*+ BROADCAST(t12) */ * from t12, t2 where t12.key = t2.key
)
- 打散数据:假设表 A 和表 B 都有 id、value 字段,现在对这两个表按照 id 进行 join 操作,即 A.id = B.id。此时,因为 id 都为 a,所有数据会在一个 task 上进行关联操作,这样就出现了数据倾斜。处理方法就是将大表 A 中的 id 加上后缀 0 - n,起到打散的作用,为了结果正确,小表 B 中的 id 需要将每条数据都复制 n 份。如下图所示,正是由于小表 B 复制了多份,所以无论大表 A 打上哪个随机后缀,都可以保证能跟小表 B 中的某一条数据 join 上。此时再进行 join 操作,将会产生 3 个 task,每个 task 只需要关联一条数据,起到分散的作用。
-- 表A
select id, value, concat(id, (rand() * 10000) % 3) as new_id
from A
-- 表B
select id, value, concat(id, suffix) as new_id
form (
select id, value, suffix
from B Lateral View explode(array(0, 1, 2)) tmp as suffix
)
自适应查询执行AQE
Spark 3.0 优化查询性能的另一利器是自适应查询执行(Adaptive Query Execution,简称 AQE),它可以在查询执行过程中动态地调整查询计划,以提高查询性能。一旦启用 AQE(spark.sql.adaptive.enabled=true),Spark SQL 会采用以下策略来优化查询:
- 动态调整 shuffle 分区数:在执行 shuffle 操作时,Spark SQL 会根据数据量和集群资源动态调整 shuffle 分区数,以避免资源浪费和数据倾斜。
- 动态调整 join 策略:Spark SQL 会根据数据大小和 join 条件的复杂度动态选择 join 策略,以提高查询性能。
- 动态调整 Broadcast Join 阈值:Spark SQL 会根据数据大小和集群资源动态调整 Broadcast Join 的阈值,以避免数据倾斜和 OOM。
- 动态调整数据倾斜处理策略:当查询出现数据倾斜时,Spark SQL 会自动调整数据倾斜处理策略,以避免查询失败。
总之,启用 AQE 可以大大提高 Spark SQL 查询的性能和稳定性。但需要注意的是,自适应查询优化器可能会造成一些额外的开销,因此在使用时需要根据实际情况进行权衡。