
环境准备
开发环境准备(Java/Scala)
准备项 说明 安装JDK JDK 8、JDK 11 ,推荐使用 konaJDK,下载地址 安装 Scala Scala 2.12,下载地址 安装和配置 IDE 按需选择,比如 IntelliJ IDEA 或 Eclipse 安装 Maven 开发环境基础配置,负责构建 Java 应用程序 Maven 配置准备 如果需要本地调试,需要配置 Maven pom.xml,推荐 Maven 3.6.3,下载地址 远程调试环境准备
以下使用 Linux 环境作为开发机进行应用调试说明。
- 准备开发机(可选):建议使用 Linux 操作系统
- 部署客户端:在开发机上执行客户端部署
- 导入示例工程代码
以 IntelliJ IDEA 为例,将示例工程代码导入进行说明。
- 下载样例代码,选择对应迭代分支:https://g-necm8077.coding.net/public/tencentcloud-tbds-examples/tbds-examples/git/files/master
- 导入项目:安装完 IntelliJ IDEA 和 JDK 工具后,导入样例工程到 IntelliJ IDEA 开发环境。点击 Open 后,选择上一步下载的项目地址打开
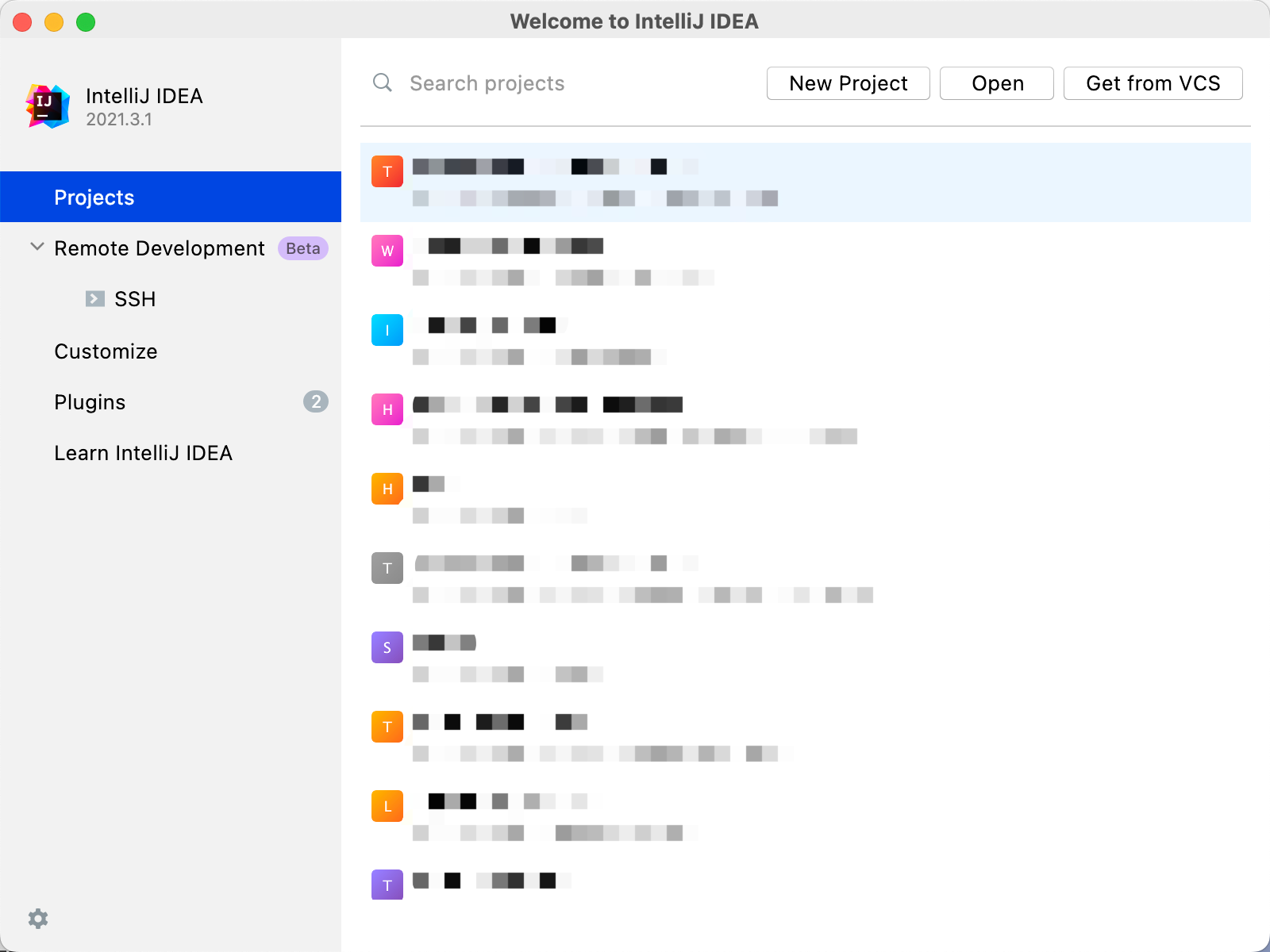
- IDEA 配置 JDK:首先确保在本地安装了 JDK 1.8,并配置好了环境变量。IDEA 选择 File 下的 Project Structure,点击 SDKs,选择 JDK 1.8,点击 Apply,再点击 OK。若没有 JDK 1.8,则点击 + 号进行添加,点击 Add JDK 后选择 JDK 1.8 安装目录,然后点击 OK 即可。
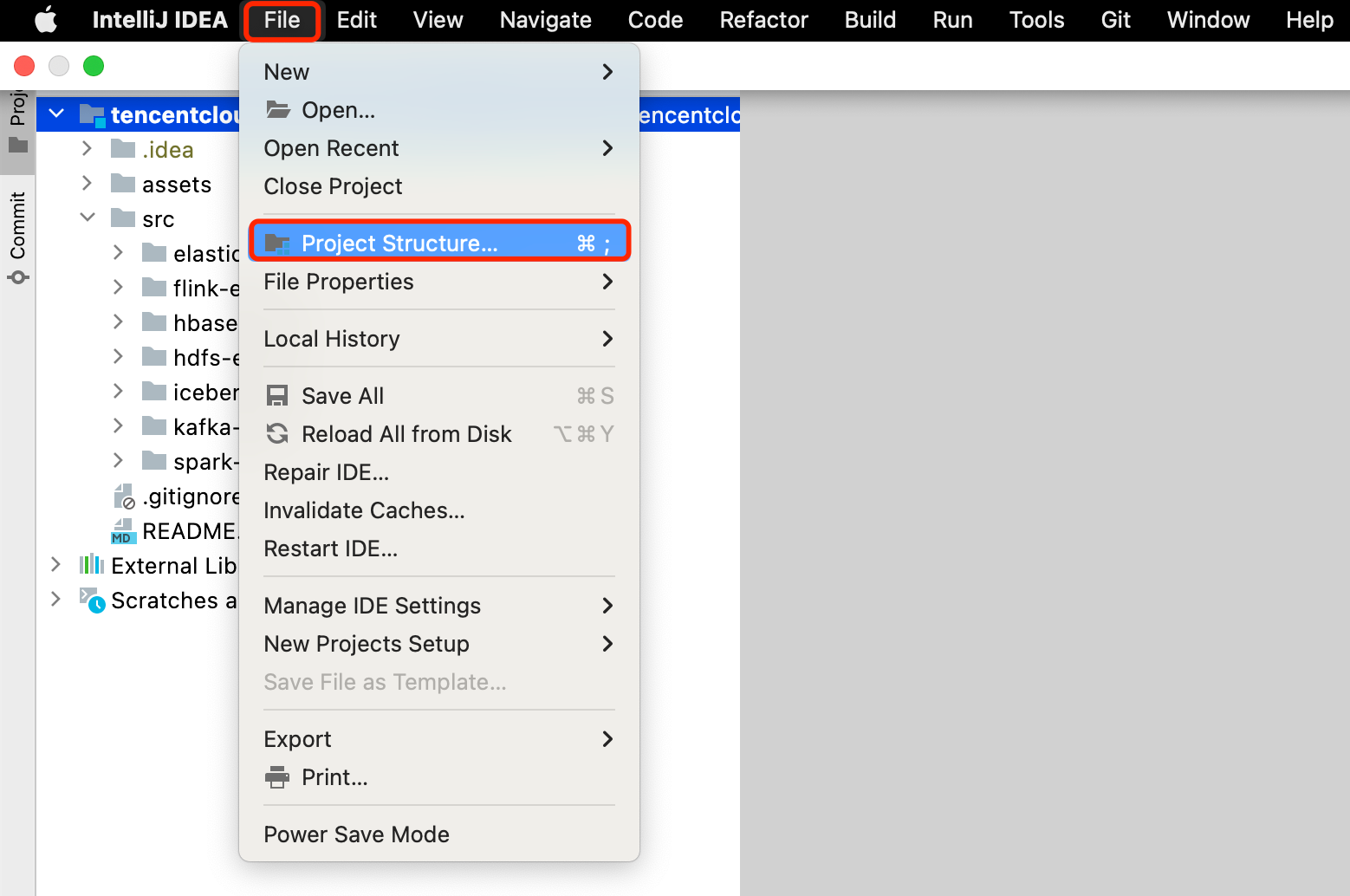
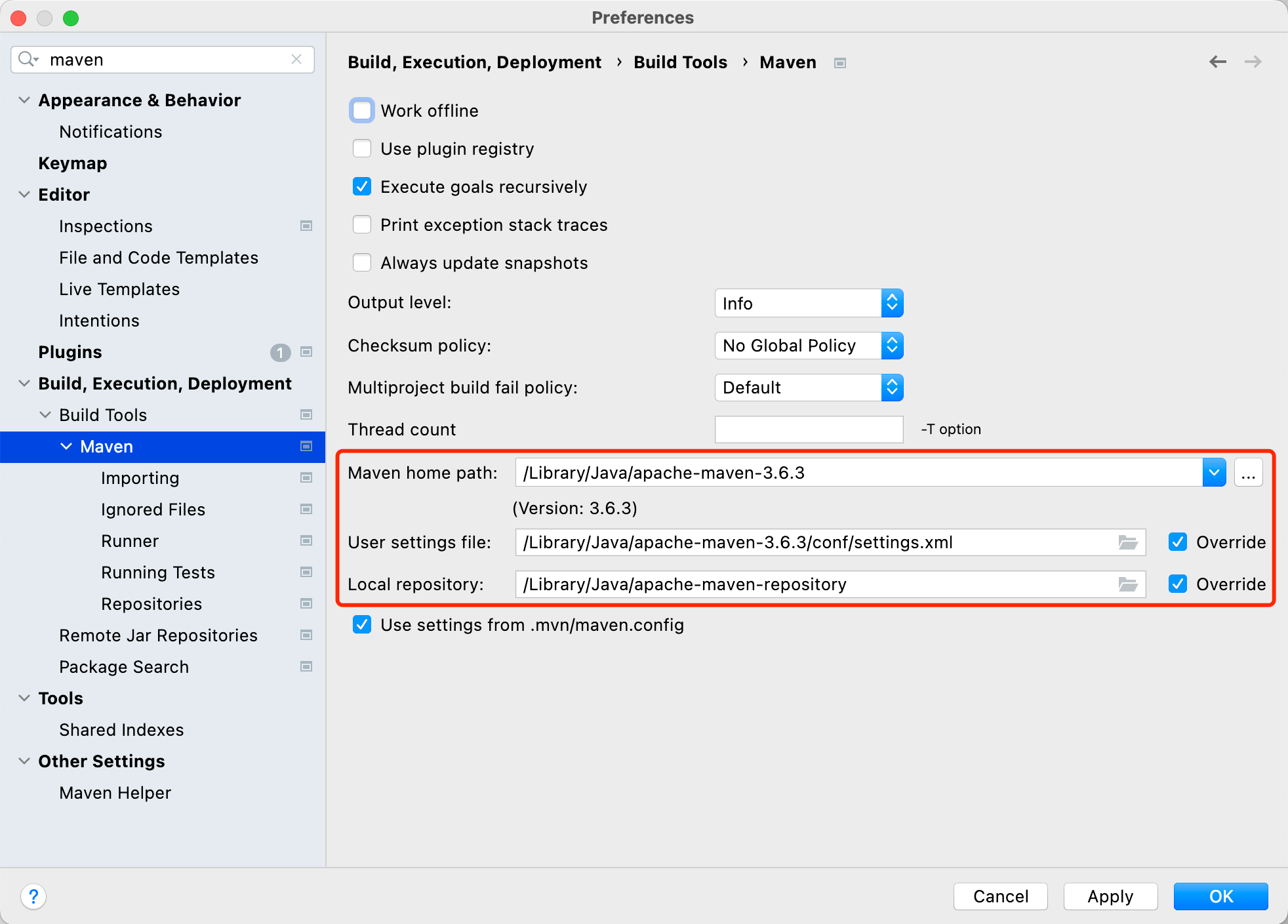
- IDEA 配置 Maven:首先确保在本地安装了 Maven,并配置好了环境变量和 settings.xml 文件。IDEA 点击 Settings 进入配置页面,左上角输入 maven 进行搜索,点击 Build Tools 下的 Maven 配置项,修改 “Maven home path” 为本地 Maven 的安装目录,修改 “User settings file” 为本地 Maven settings.xml 配置文件的文件路径,并勾选 Override,此时 “Local repository” 将自动设置为 settings.xml 文件中配置的本地 Maven 仓库的目录。最后点击 Apply,再点击 OK。
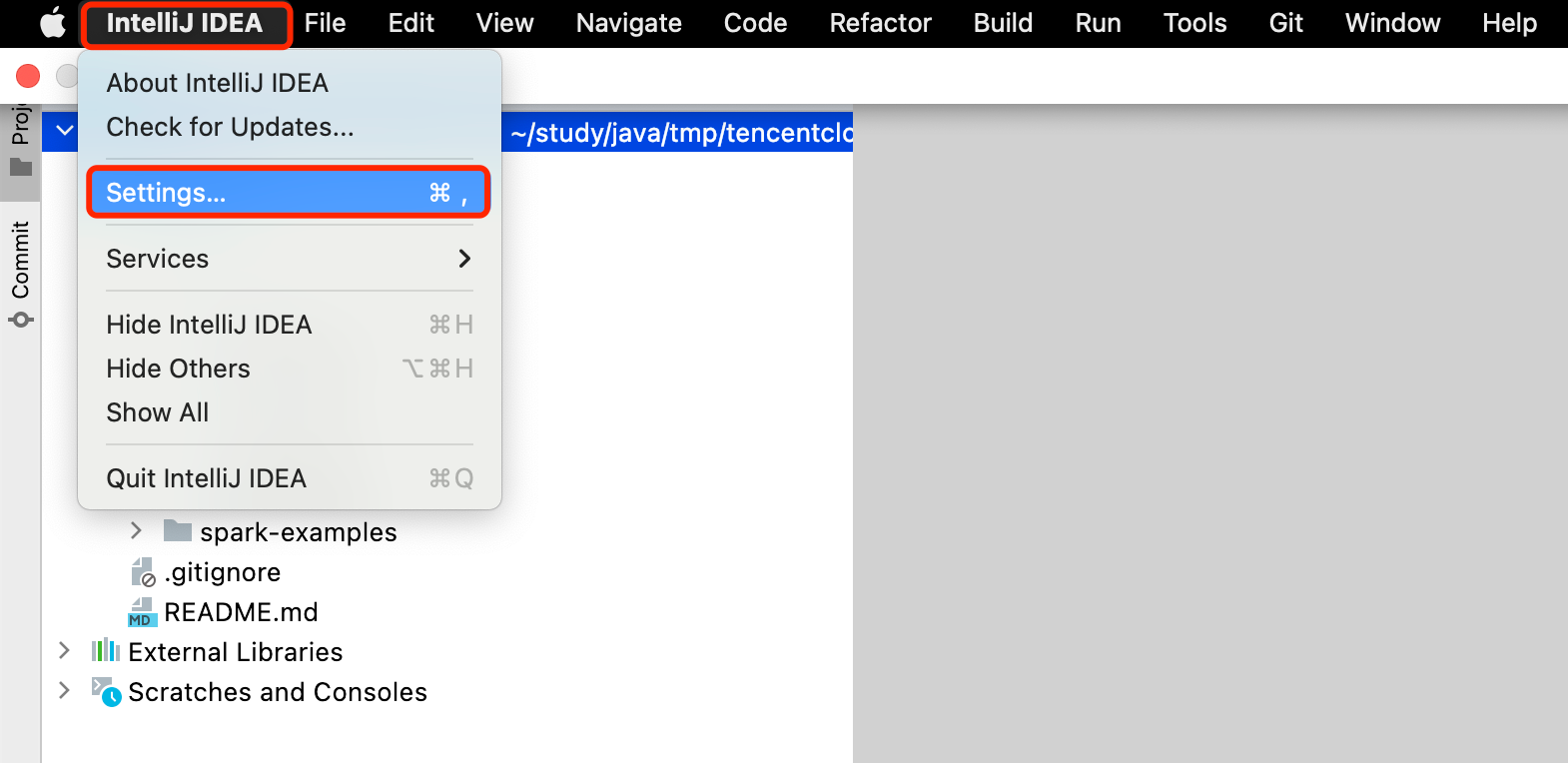
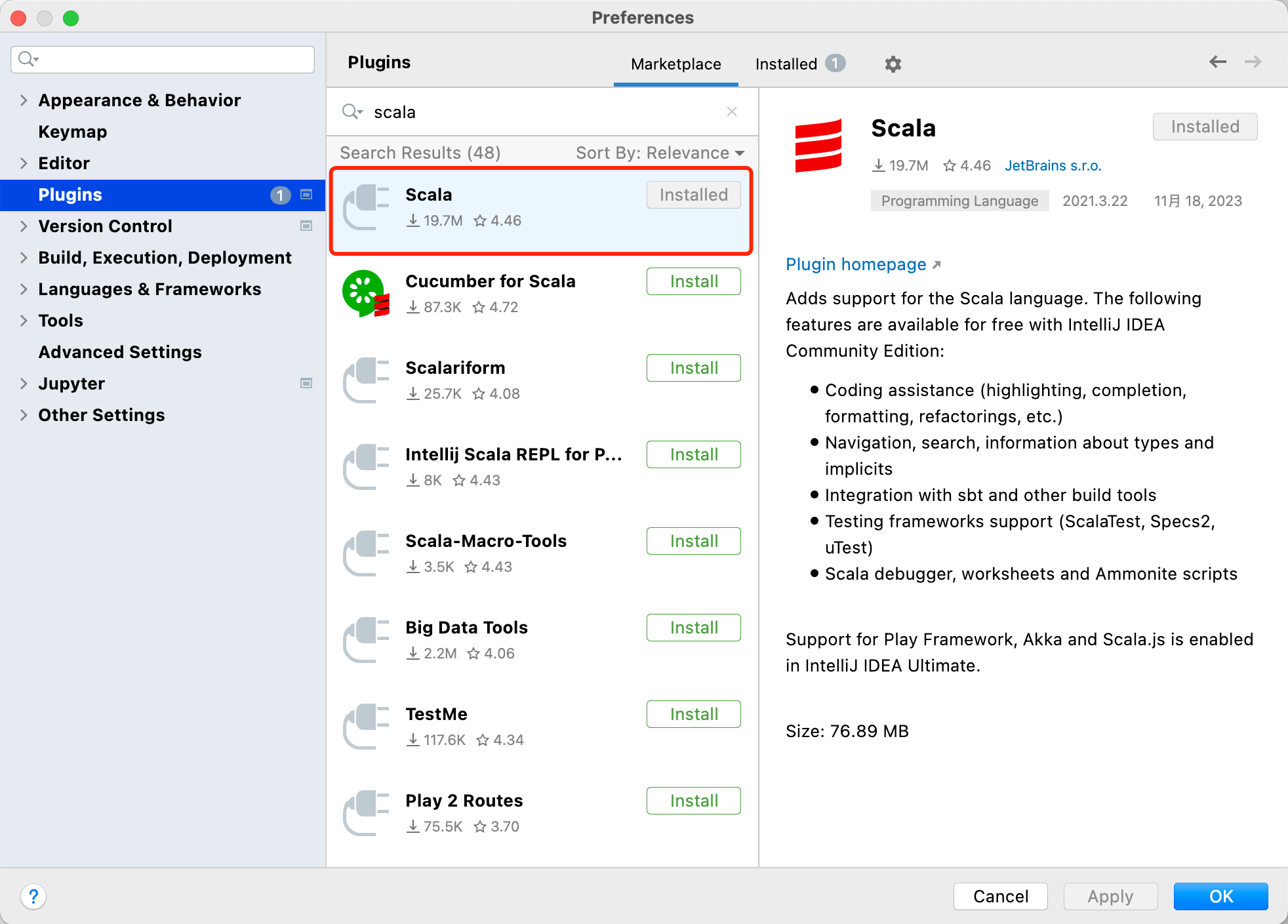
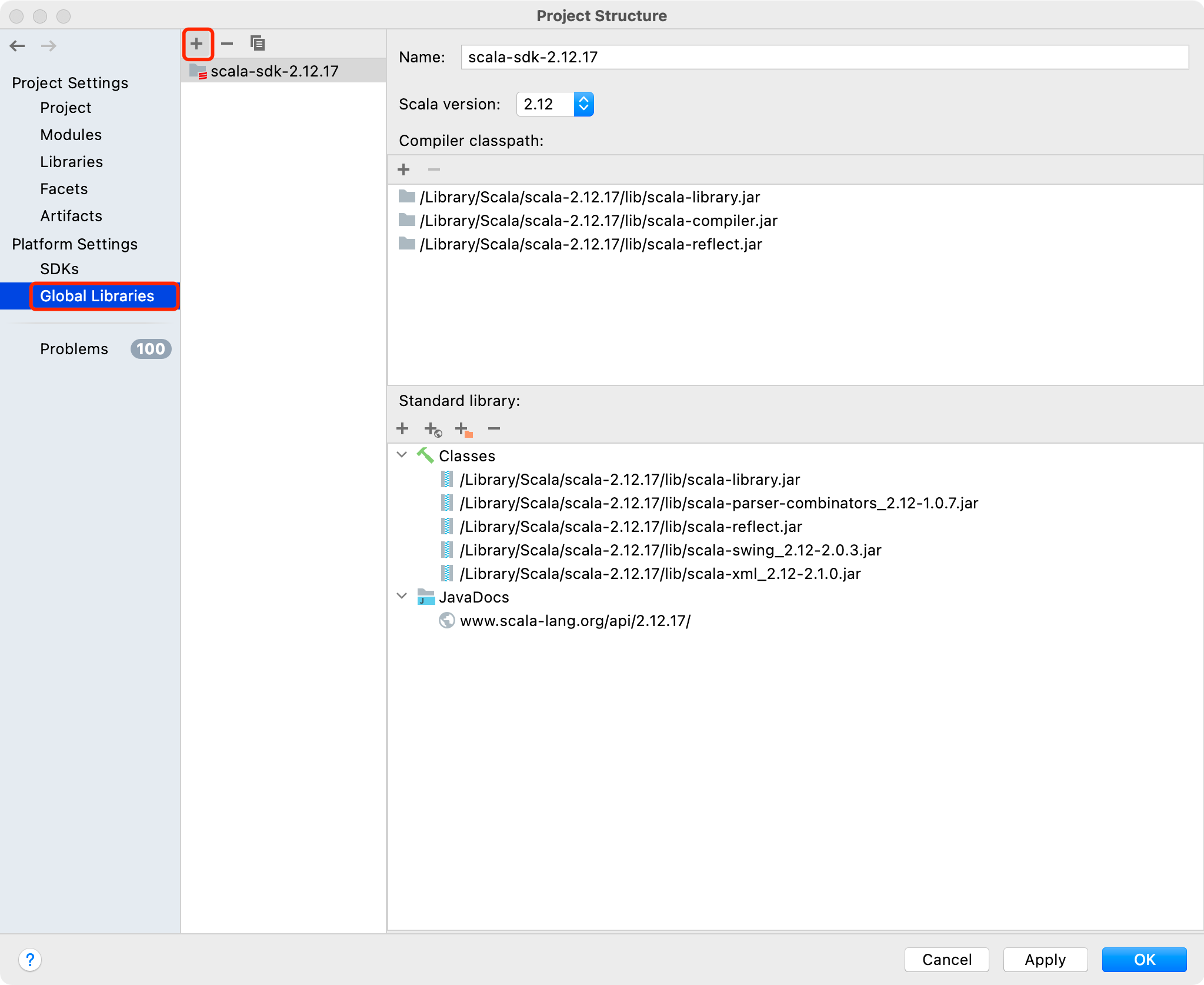
- IDEA 配置 Scala(可选):首先确保在本地安装了 Scala,并配置好了环境变量。同样地,IDEA 点击 Settings 进入配置页面,点击 Plugins,右侧窗口选择 Marketplace,搜索 scala 插件并安装,安装后重启。重启后,继续选择 File 下的 Project Structure,点击 "Global Libraries",点击 + 号添加 Scala SDK,选择本地 Scala 2.12 安装目录,点击 Apply,再点击 OK 即可。







代码调试
以下使用 IntelliJ IDEA 说明示例工程代码调试过程。
- 编译和运行代码
- 先在本地准备一份需要单词统计的文件,文件内容如下。假设文件名为 wordcount.txt,文件绝对路径为 /tmp/wordcount.txt。
hello world
hello spark
hello hadoop
scala java
java kyuubi
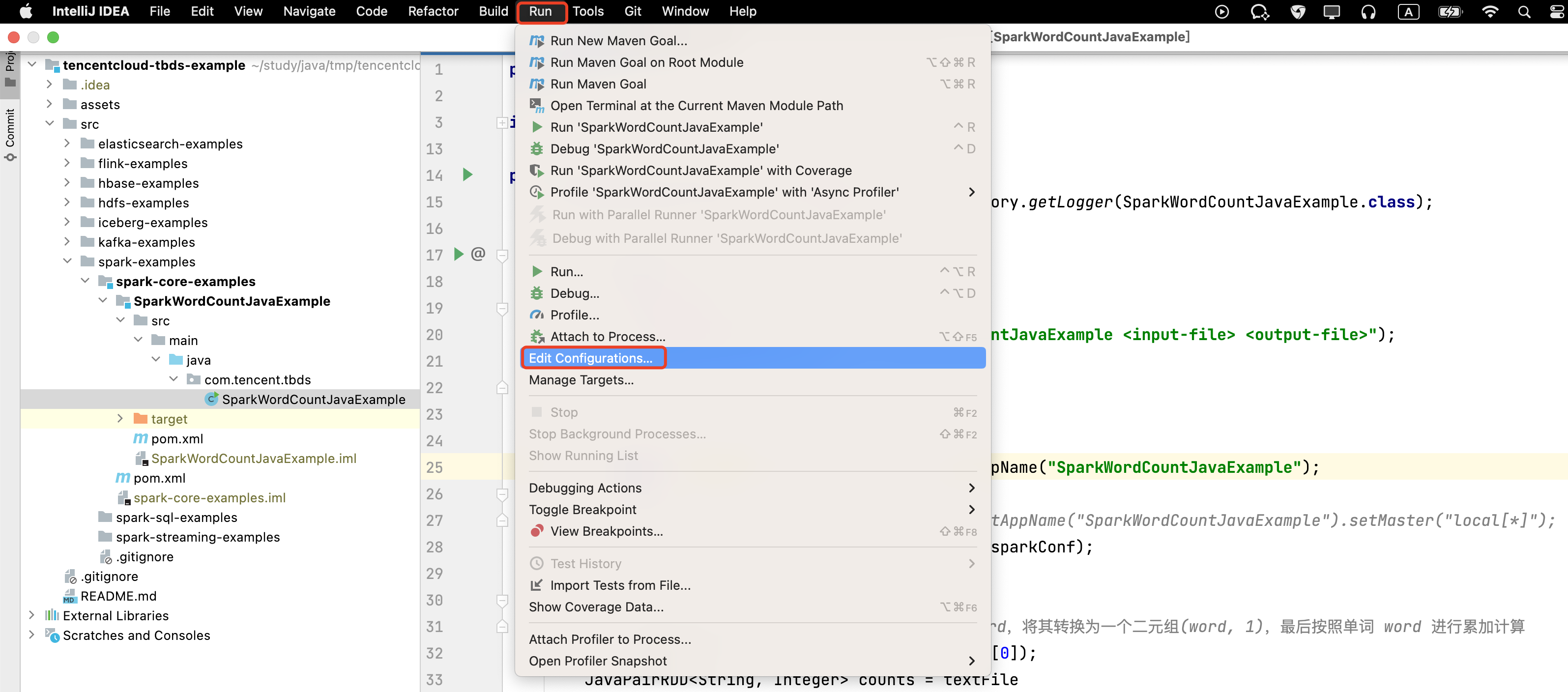
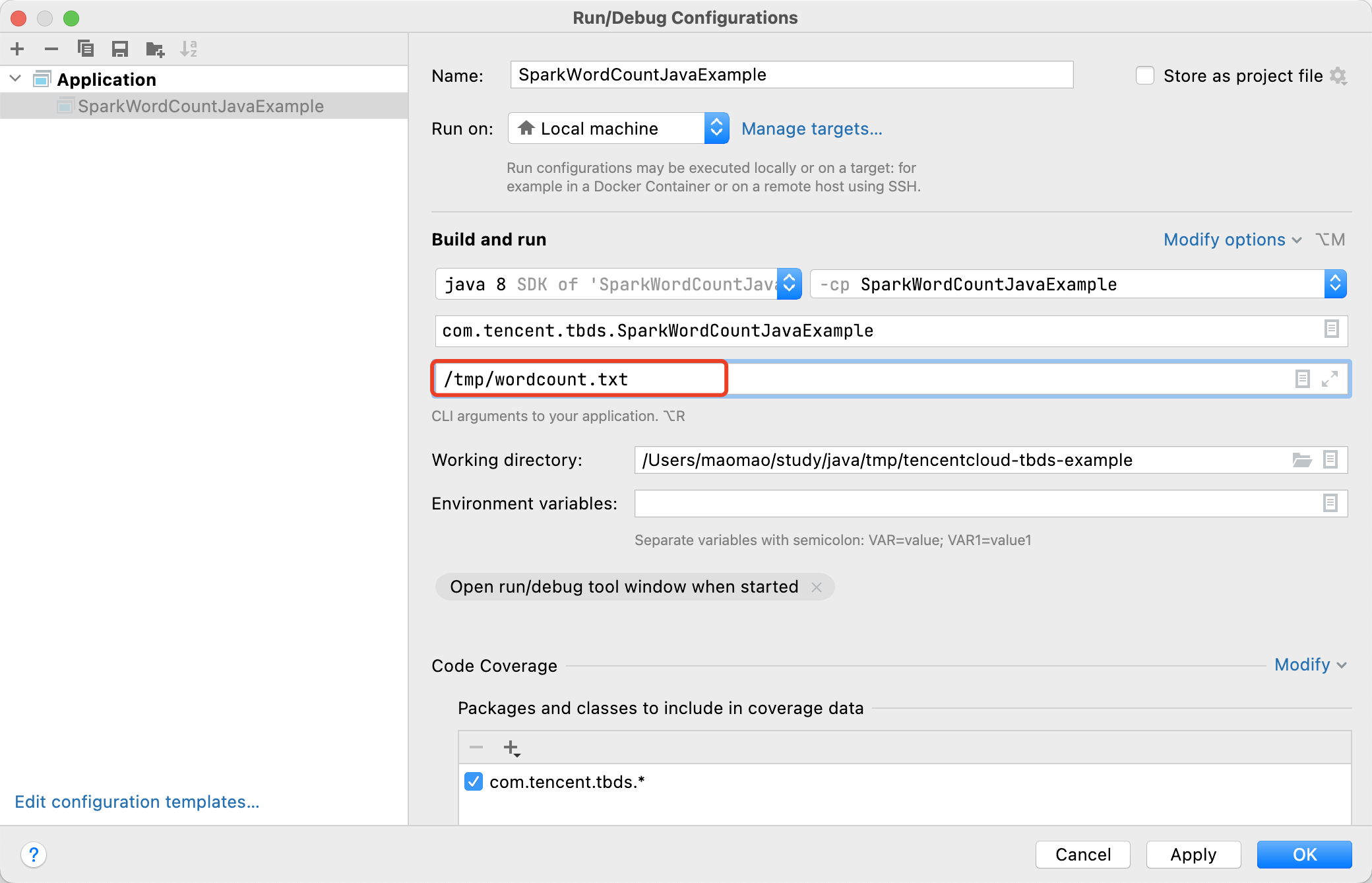
- 选择 Run下面的 Edit Configurations,若不存在 Application,则点击 “+” 号新建,内容如下图所示,并在 Program arguments 一列中输入参数,多个参数使用空格分隔,这里的参数表示要进行单词统计的本地文件路径,以及单词统计最终结果的保存目录(可选),这里填写的是 /tmp/wordcount.txt,然后点击 Apply。


- 本地调试
将示例代码中的本地调试注释打开,同时注释上一行代码,如下所示。local[*] 表示使用与逻辑核心数相同的工作线程在本地运行 Spark,若在代码中未进行设置,则需要在提交任务时或配置文件中进行指定。这是由于参数具有优先级:直接在 SparkConf 中设置的属性优先,然后是传递给 spark-submit 或 spark-shell 的参数,最后是 spark-defaults.conf 配置文件中的选项参数。
// 初始化Spark上下文
// SparkConf sparkConf = new SparkConf().setAppName("SparkWordCountJavaExample");
// 本地调试
SparkConf sparkConf = new SparkConf().setAppName("SparkWordCountJavaExample").setMaster("local[*]");
IDEA 点击 Run 即可在本地调试运行代码,调试结果如下图所示。在代码本地运行过程中,还可以查看 Spark web UI 监控页面,即图中日志输出的蓝色字体 URL,一旦代码运行结束,该 URL 将失效。
- 开发机调试
确保代码中有必要的日志输出,开发机调试参考下一节【打包发布】。 注意,开发机调试和本地调试使用场景略有不同,总的来说,开发机调试更解决实际的应用场景。比如,这里本地调试没有 HDFS 配置文件,无法访问 HDFS,因此读取的是本地文件;而开发机上可以直接访问 HDFS,读取的是 HDFS 文件。
打包发布
- 打包
以下使用 IntelliJ IDEA 说明示例工程代码编译过程。点击 IDEA 下方 Terminal 打开终端,切换到示例工程的 Spark 工程目录下,然后使用命令 mvn clean install 对工程进行打包,运行过程中可能还需要下载一些文件,直到出现 build success 表示打包成功。
cd src/spark-examples/spark-core-examples/
mvn clean install
通过上述编译打包后,将在工程目录下 target 文件夹中看到打好的 jar 包,如图示中的 SparkWordCountJavaExample-1.0.jar。注意,这里没有将项目依赖的第三方 JAR 一起打包,若开发机上不存在项目中依赖的第三方 JAR,读者可参考网上教程将项目打包成 FatJar,或将依赖的第三方 JAR 上传至开发机,然后在使用 spark-submit 提交任务时,通过 --jars 参数进行指定,参数说明参考【常用命令】。
- 开发机运行
- 准备用户:获取用户认证信息。若是 Kerberos 环境,需要将用户的 keytab 文件下载到本地,然后上传至开发机。这里将 test 用户的 test.keytab 文件上传至开发机的 /tmp 目录。
- 准备文件:准备一份名为 wordcount.txt 的单词统计文件,然后将该文件上传至 HDFS /tmp 目录。注意,如果是 kerberos 环境,需要首先进行认证。
# 1. Kerberos认证(Simple认证跳过该步)
[test@10 ~]$ klist -kt /tmp/test.keytab
Keytab name: FILE:/tmp/test.keytab
KVNO Timestamp Principal
---- ------------------- ------------------------------------------------------
1 11/22/2023 17:00:59 test@TBDS-CURPL8E5
1 11/22/2023 17:00:59 test@TBDS-CURPL8E5
[test@10 ~]$ kinit -kt /tmp/test.keytab test@TBDS-CURPL8E5
# 2. 准备单词统计文件,内容如下,编辑后保存退出
[test@10 ~]$ vim /tmp/wordcount.txt
hello world
hello spark
hello hadoop
scala java
java kyuubi
# 3.上传单词统计文件至HDFS
[test@10 ~]$ /usr/local/service/hadoop/bin/hdfs dfs -put /tmp/wordcount.txt /tmp
Ranger 授权:确保 test 用户具有提交 yarn default 队列的权限。
安全认证:Spark Kerberos 环境认证方式有三种,如下表所示。
认证方式 认证说明 命令认证 在提交 Spark 任务前,使用 kinit -kt {keytab} {principal} 命令进行认证 配置认证 以下三种方式任选其一,推荐方式一和方式二 - 在 spark-submit 命令提交任务时,通过 --conf spark.kerberos.keytab={keytab} --conf spark.kerberos.principal={principal} 参数指定
- 在 spark-submit 命令提交任务时,通过 --keytab {keytab} --principal {principal} 参数指定
- 在 spark-defaults.conf 配置文件中,配置 spark.kerberos.keytab 和 spark.kerberos.principal 参数
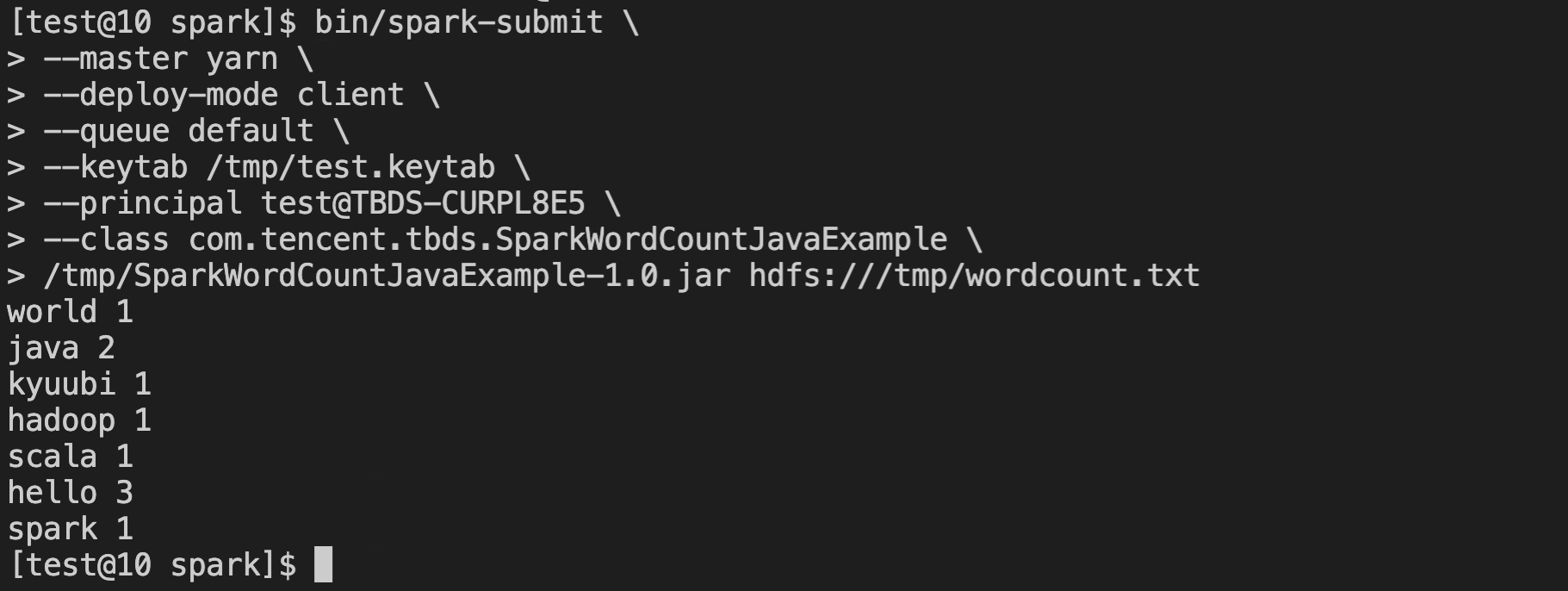
代码认证 获取用户的 keytab 和 principal 后,在应用程序的代码中进行认证 运行样例:将该 jar 包上传到开发机 /tmp 目录,进入 Spark 安装目录,一般位于 /usr/local/service/spark,然后使用 spark-submit 命令提交,最后的 HDFS 路径参数表示需要进行单词统计的文件的绝对路径。若项目依赖第三方 JAR,可以通过 --jars 参数进行指定,更多参数说明参考【常用命令】。注意,这里演示的是通过“配置认证”的方式提交 Spark 任务,读者可根据自身情况自行选择认证方式。
[test@10 ~]$ cd /usr/local/service/spark
[test@10 spark]$ bin/spark-submit \
--master yarn \
--deploy-mode client \
--queue default \
--keytab /tmp/test.keytab \
--principal test@TBDS-CURPL8E5 \
--class com.tencent.tbds.spark.SparkWordCountJavaExample \
/tmp/SparkWordCountJavaExample-1.0.jar hdfs:///tmp/wordcount.txt
- 当以 yarn client 模式提交,运行过程中的日志和结果将直接输出至控制台,如下图所示。由于日志级别为 WARN,因此这里没有输出日志。如果是在集群外进行作业提交,两个集群间没有做 hostname 通信的话需要指定 Driver 实际的 IP 地址,例如:--conf spark.driver.host=xx.xx.xx.xx。

程序运维监控
- 监控
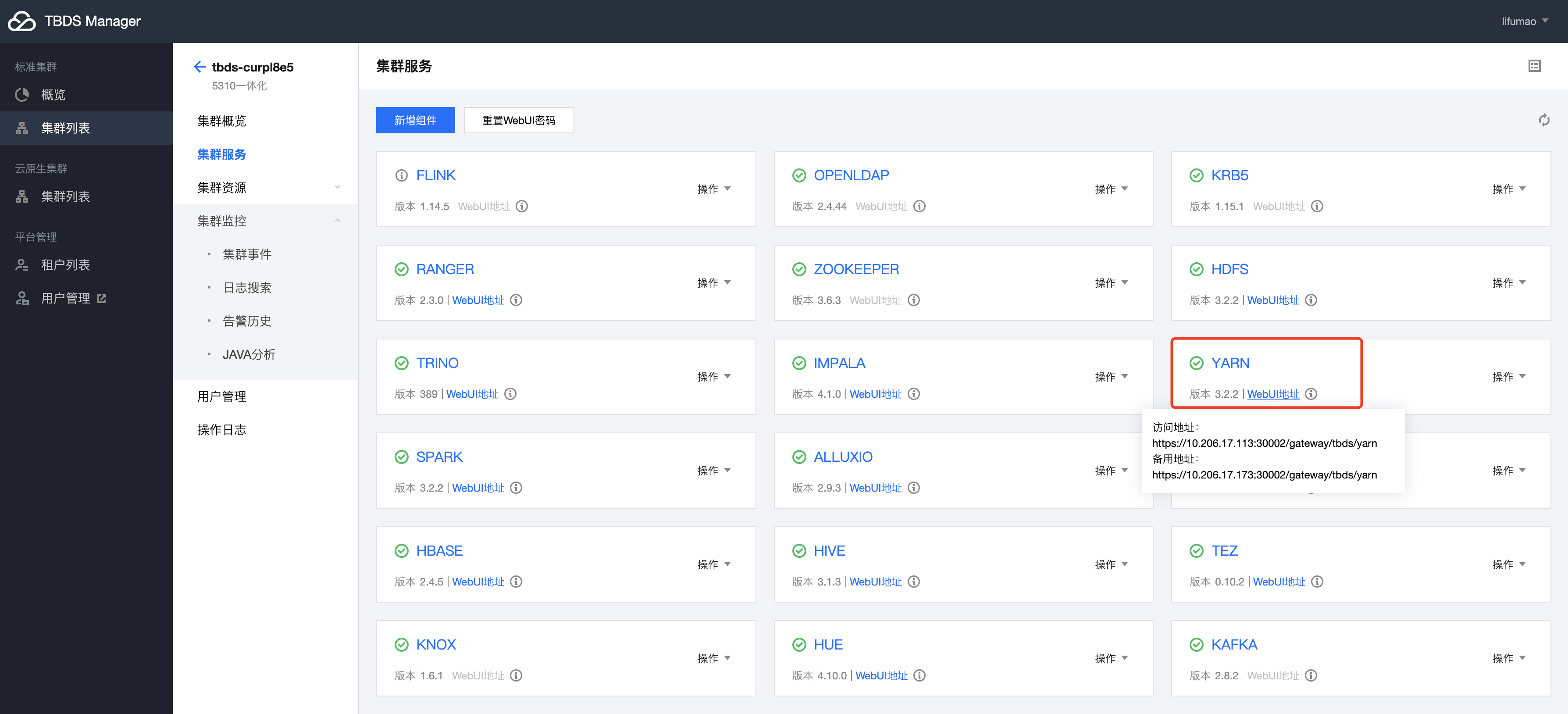
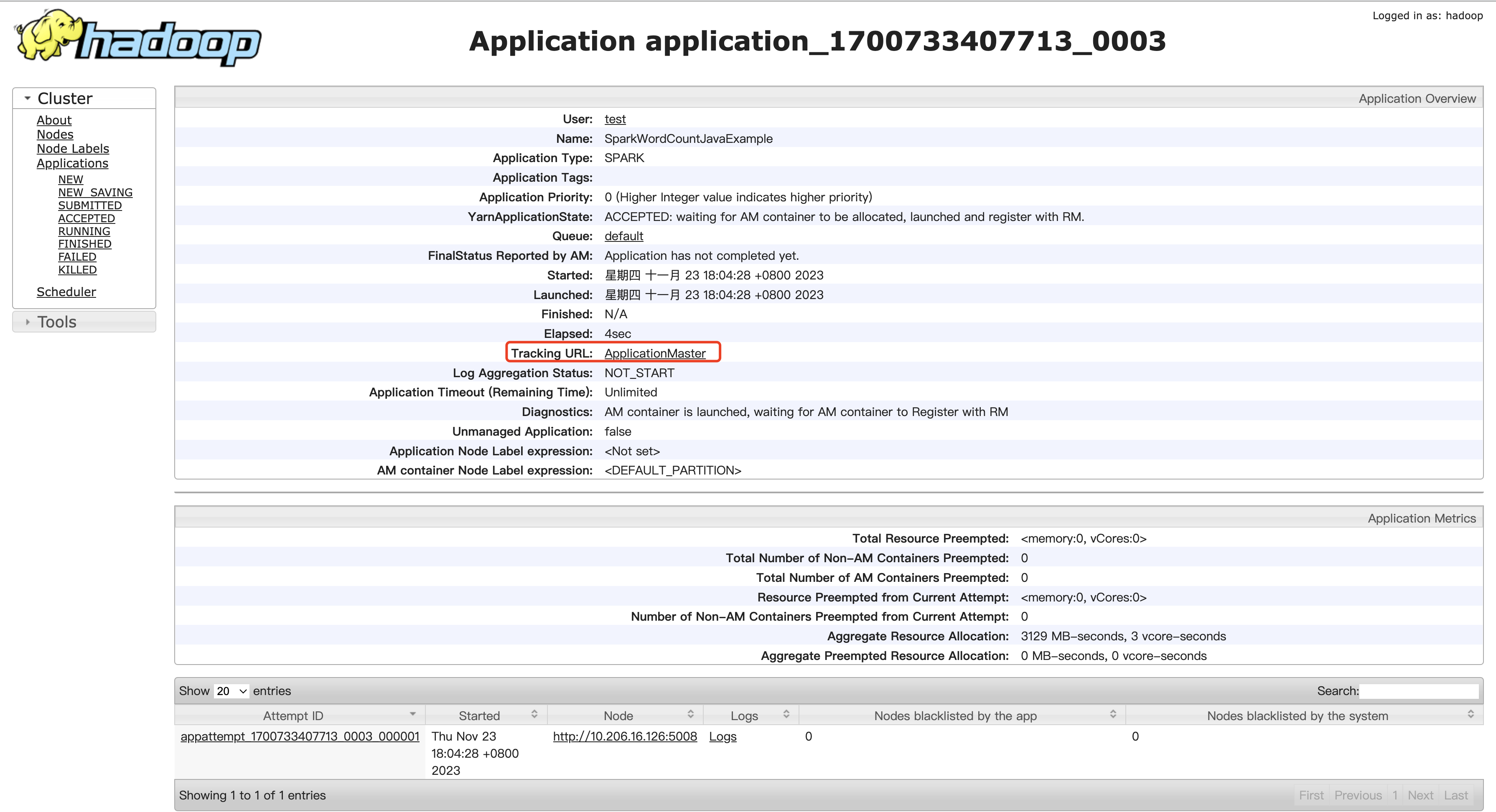
- 登录 TBDS Manager 管控平台,点击“集群列表”,选择 Spark 程序运行所对应的集群。点击“集群服务”,选择 YARN 服务,点击 WebUI 地址跳转至 YARN UI 界面。
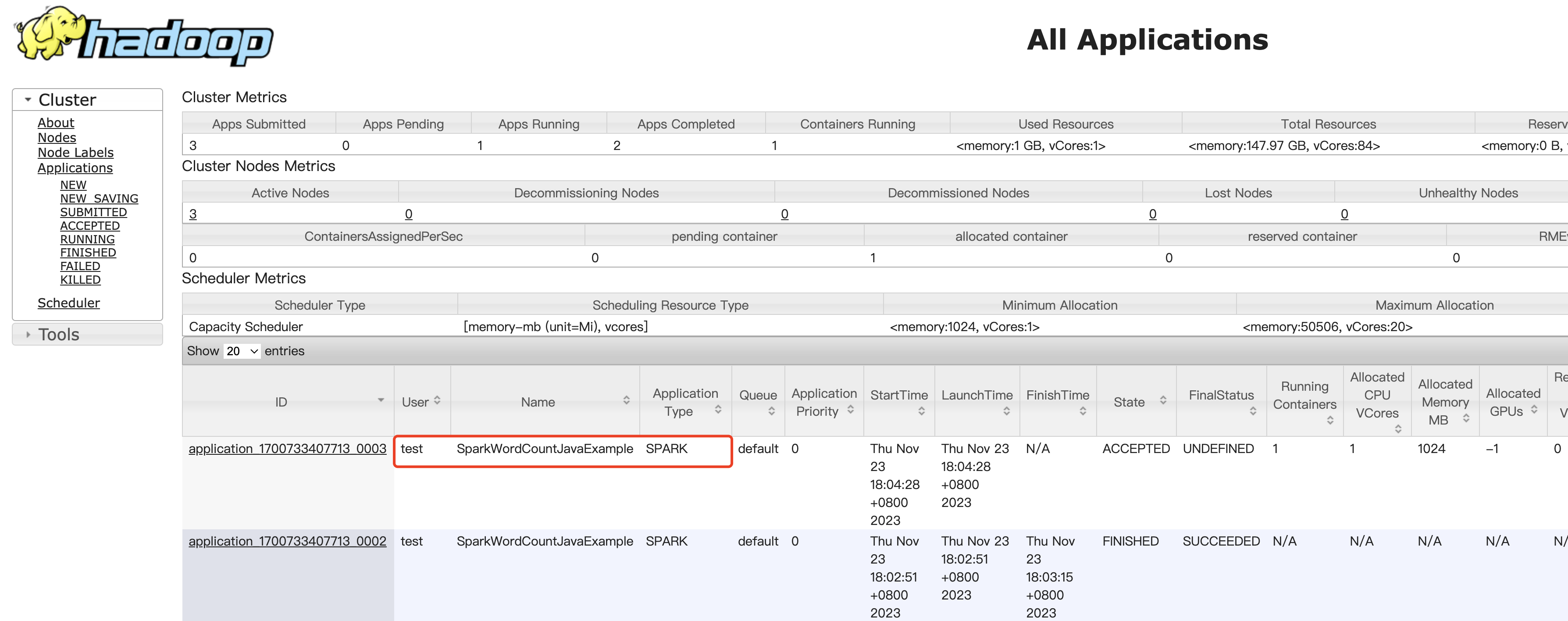
- YARN UI 页面根据 ApplicationID、User、Name 等信息,找到对应的 Spark 任务。Spark 任务的 ApplicationID 在日志级别为 INFO 及以下会输出至控制台,也可以根据任务名 SparkWordCountJavaExample 等信息进行查找对应的 Spark 任务,点击 applicationID 链接,然后点击 Tracking URL 链接,跳转 Spark 作业监控页面。
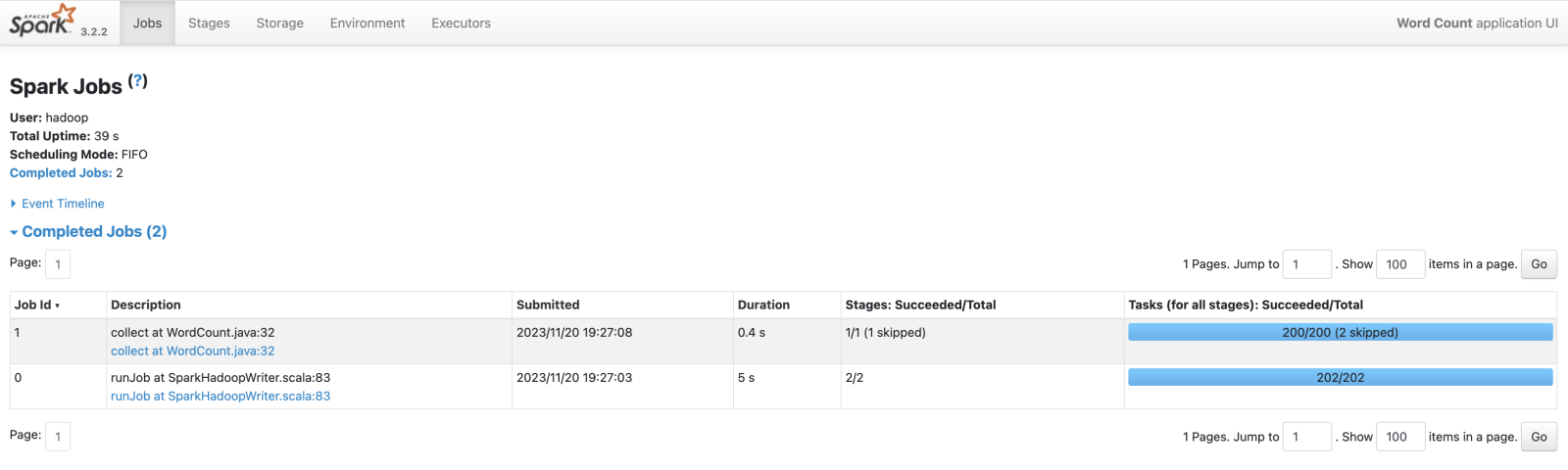
- Spark 监控页面大致如下,更多介绍详见 Spark 官网。




日志查看
若任务以 yarn client 模式提交,则日志将直接输出至控制台。若任务以 yarn cluster 模式提交,则需要到 YARN UI 页面根据 ApplicationID、Name 等信息,找到对应的 Spark 任务,点击 Logs 查看日志。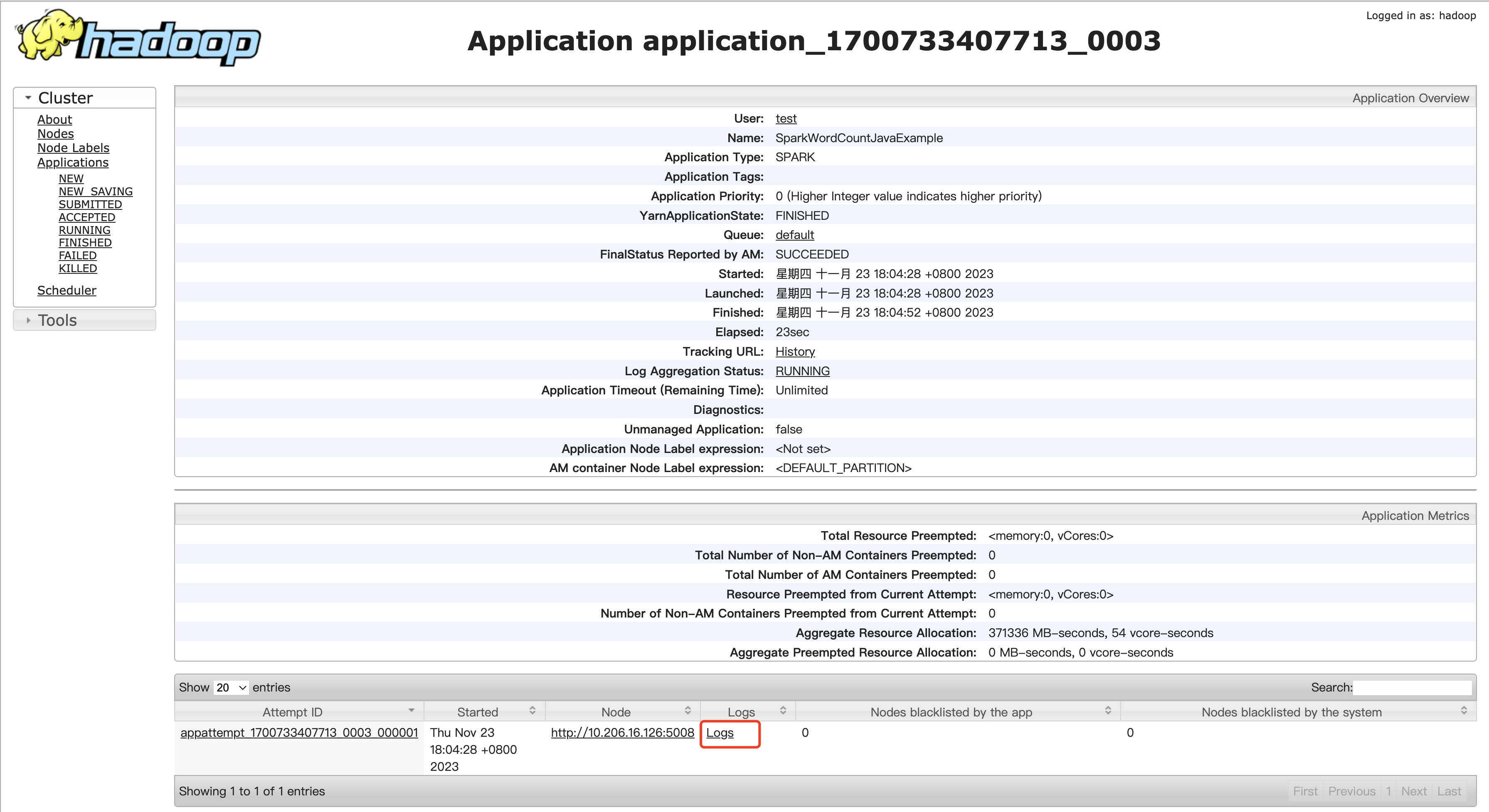
作业操作
与其它提交至 YARN 的任务类似,可以通过 YARN 相关命令查看、停止任务。例如,通过命令 yarn application -kill 停止 Spark 应用;通过命令 yarn logs -applicationId 查看 Spark 任务日志(Cluster 模式)。
