
简要介绍
TBDS-ES 支持冷热温分层存储策略,核心通过 节点属性标记 + 索引生命周期管理(ILM) 实现数据按访问频率自动分配到不同性能的节点,平衡性能与成本。
热温冷架构常用于日志或指标类的时序数据。例如,假设正在使用 ES 聚合来自多个系统的日志文件,今天的日志正在频繁地被索引,且本周的日志搜索量最大(热)。上周的日志可能会被频繁搜索,但频率没有本周日志那么高(温)。上月日志的搜索频率可能较高,也可能较低,但最好保留一段时间以防万一(冷)。
ES 热温冷数据生命周期示例
如上图集群有 19 个节点:10 个热节点、6 个温节点和 3 个冷节点(实际使用 ILM 实现热温冷架构至少需要有 2 个节点),其中冷节点是可选的,它只是多提供一个建模级别来表示数据的存放位置。ES 允许用户定义哪些节点是热节点、温节点或冷节点,ILM 允许用户定义何时在两个阶段之间移动,以及在进入哪个阶段时如何处理索引。比如在日志、监控、时序数据等场景中,数据的访问频率随时间递减(“热数据”→“温数据”→“冷数据”):
- 热数据:最近 7 天内的数据,需高并发写入、低延迟查询(如实时监控告警),需高性能硬件。
- 温数据:7~30 天的数据,查询频率降低(如周级报表),可接受稍高延迟,用中性能硬件。
- 冷数据:30 天以上的数据,极少查询(如合规归档),可牺牲查询速度换存储成本,用低成本硬件。
分层架构通过将不同数据分配到对应节点,避免 “用 SSD 存储冷数据” 的资源浪费,同时避免 “用 HDD 存储热数据” 的性能瓶颈。
对于热温冷架构,ES 集群中的节点规格配置并不是一个标准的设置,通常而言遵循:
热节点需要较多的 CPU/内存资源和较快的 IO 带宽资源
对于温节点和冷节点来说,通常每个节点会需要更多的磁盘空间,分配较小规格的 CPU/内存 资源和 IO 带宽资源。
参考实践
注意:
下文为示例参考,实际项目请联系交付工程师结合业务情况综合评估后实施。
实施前提:完成服务器资源规划准备,按节点类型分配硬件,用于 ES 集群部署安装/扩容阶段使用。例如:
| 节点类型 | CPU | 内存 | 存储介质 | 核心用途 |
|---|---|---|---|---|
| 热节点(Hot) | 高核心数(如 16 核) | 大内存(如 64GB,缓存数据) | SSD(IOPS ≥ 1000) | 写入 + 高频查询 |
| 温节点(Warm) | 中核心数(如 8 核) | 中内存(如 32GB) | HDD(7200 转,大容量) | 低频查询 |
| 冷节点(Cold) | 低核心数(如 4 核) | 小内存(如 16GB) | 超大规模 HDD | 归档查询 |
(1)创建 TBDS-ES 集群,指定节点属性
创建集群,选择《ES》集群,按需选择部署的组件,及是否开启Kerberos认证。
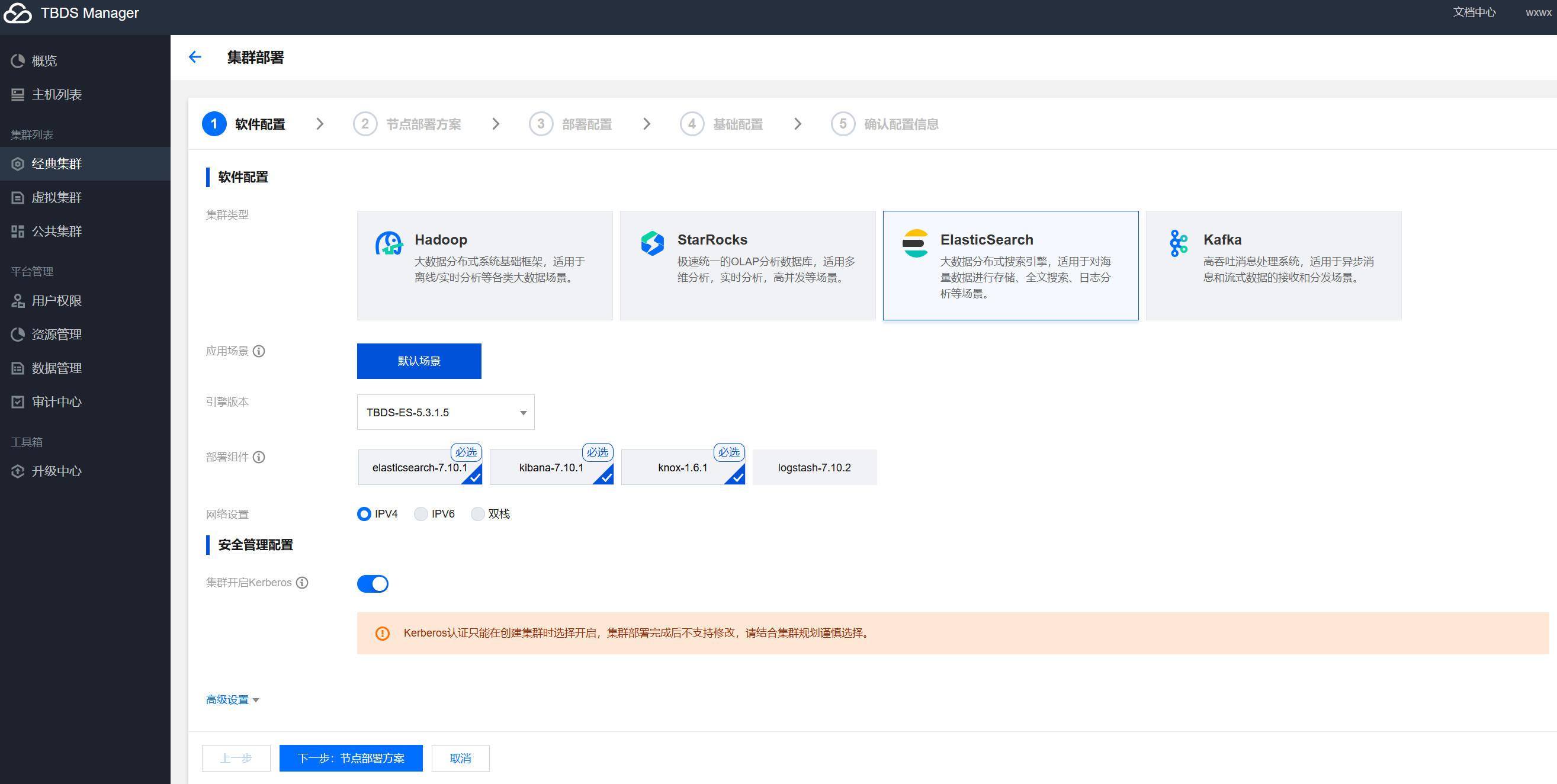
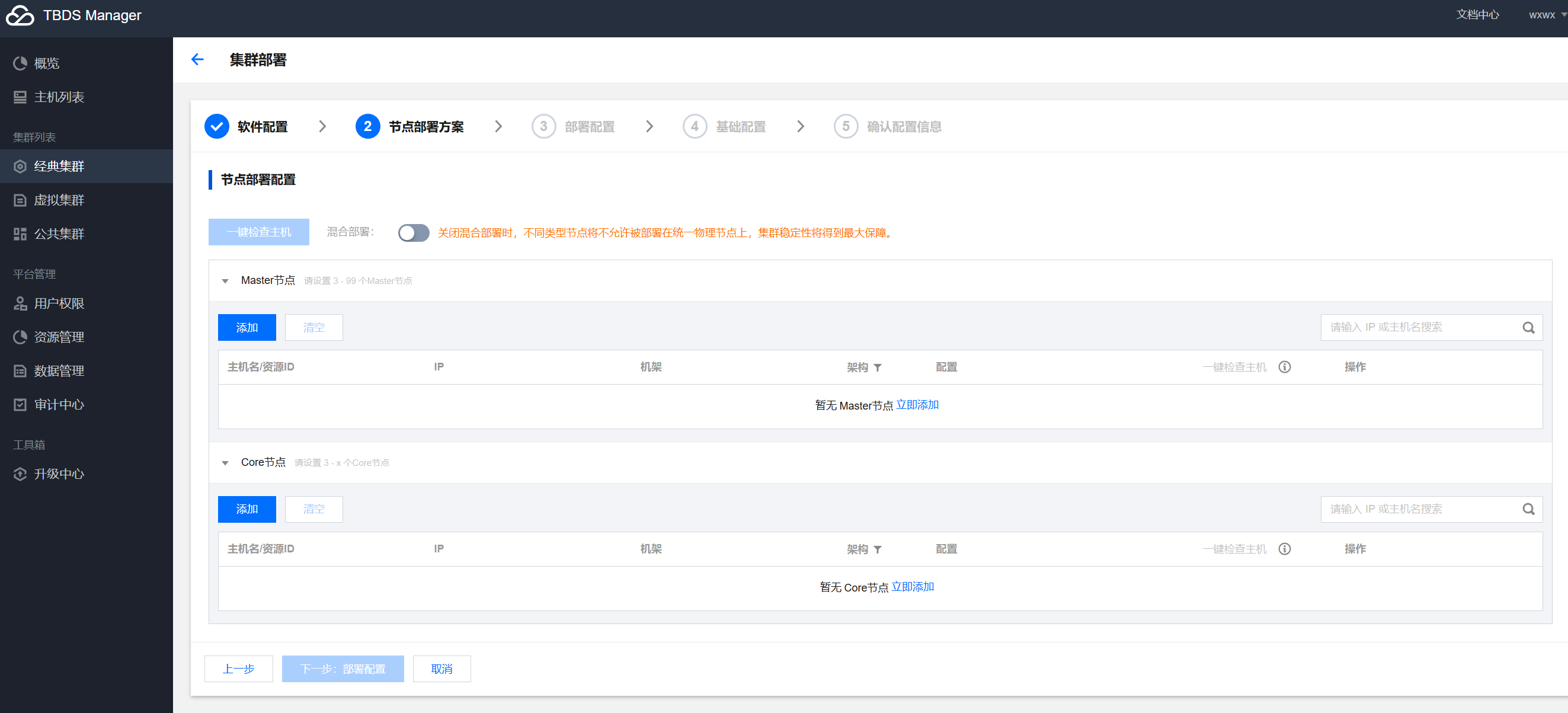
点击《下一步:节点部署方案》,根据部署场景选择是否《混合部署》,以及填写主机信息后点击下一步。
点击《下一步:部署配置》,支持打开“自定义部署”,可以调整各个节点的角色,数据节点也支持设置冷热温节点角色。
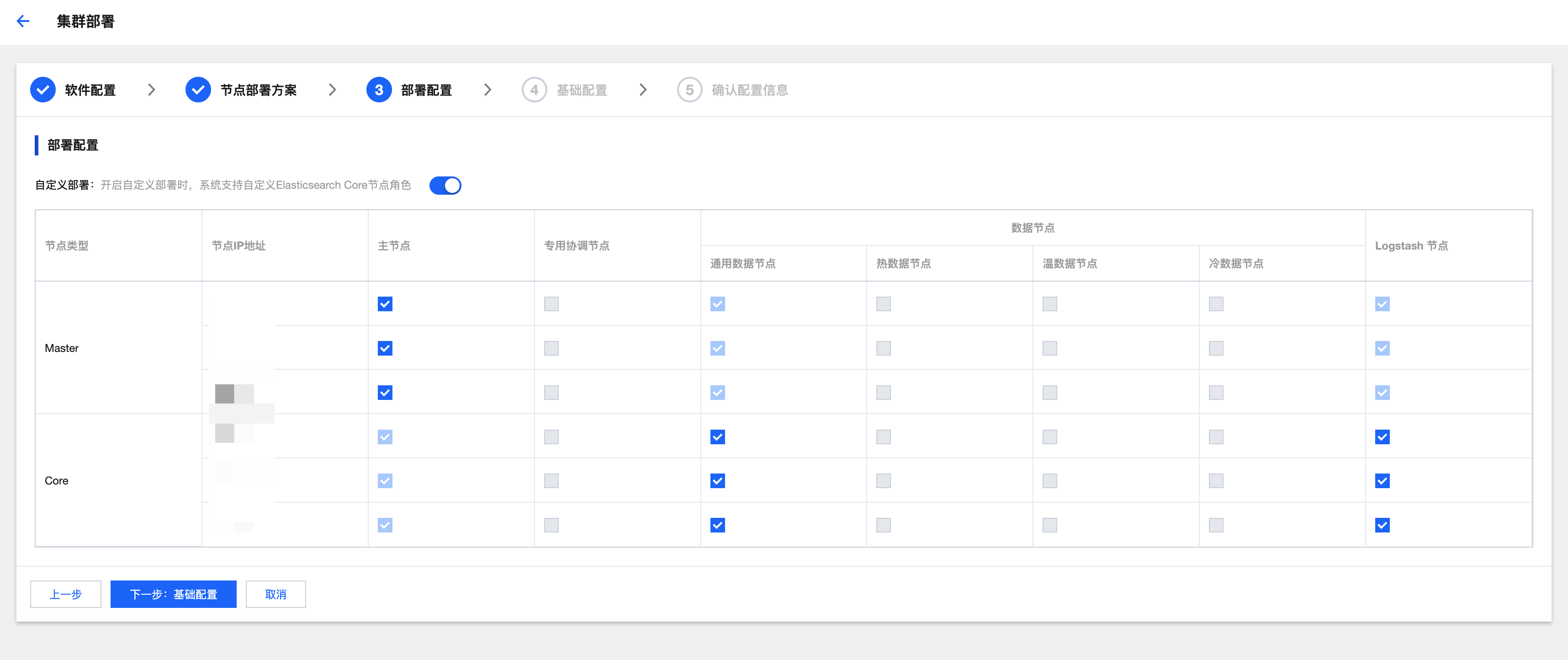
这里底层会对相应节点做打标处理,如:节点类型标签(核心,用于分片分配)node.attr.temp: hot
点击《下一步:基础配置》,填写集群名称
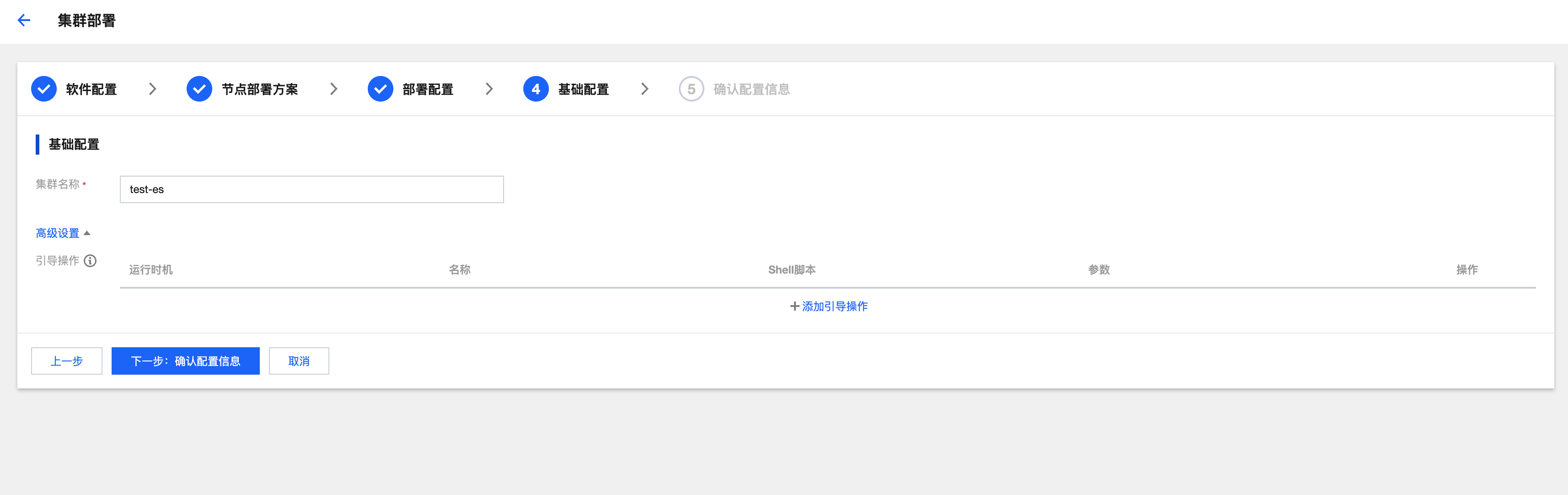
点击《下一步:确认配置信息》,检查集群配置。
点击《部署集群》,等待进度100%之后即可完成部署。




(2)配置索引生命周期管理(ILM)
说明:
TBDS-ES 的 ILM 插件可以参考:https://opendistro.github.io/for-elasticsearch-docs/docs/im/ism/policies/
- 验证节点属性是否生效(通过 API 或 Kibana):
# API查询节点属性curl -X GET "http://<es-master-ip>:9200/_cat/nodeattrs?v&h=node,attr,value"
正常返回示例:
2. 创建 ILM 策略(定义数据流转规则)
通过 Kibana 或 API 创建策略,以下是典型的日志数据策略
说明:
以下示例策略实现了热(Hot)、温(Warm)、删(Delete)工作流,您可以将此策略用作模板,根据索引的活跃程度为其分配优先资源。
在此场景中,索引初始处于热状态(Hot State)。1 天后,索引转为温状态(Warm State),此时副本数量会增加至 5 个,以提升读取性能。
30 天后,该策略会将索引移入删除状态(Delete State),随后永久删除该索引。
PUT _opendistro/_ism/policies/log-lifecycle-policy
{
"policy": {
"description": "hot warm delete workflow",
"default_state": "hot",
"schema_version": 1,
"ism_template": {
"index_patterns": ["log-*"]
},
"states": [{
"name": "hot",
"actions": [{
"rollover": {
"min_index_age": "1d"
}
}],
"transitions": [{
"state_name": "warm"
}]
},
{
"name": "warm",
"actions": [{
"replica_count": {
"number_of_replicas": 5
}
}],
"transitions": [{
"state_name": "delete",
"conditions": {
"min_index_age": "30d"
}
}]
},
{
"name": "delete",
"actions": [
{
"delete": {}
}
]
}
]
}
}
登录 Kibana 页面,查看 index policies:
3. 创建索引模板(关联 ILM 策略)
索引模板用于让新创建的索引自动应用 ILM 策略,并指定初始分片配置(热节点)。
PUT _index_template/log-template {
"index_patterns": ["log-*"],
"template": {
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1,
"index.lifecycle.name": "log-lifecycle-policy",
"index.lifecycle.rollover_alias": "log-alias"
},
"mappings": {
"properties": {
"timestamp": {
"type": "date"
},
"log_level": {
"type": "keyword"
},
"message": {
"type": "text"
}
}
}
}
}
- 创建初始滚动索引
通过 “别名 + 初始索引” 触发 ILM 的 rollover 机制
PUT log - 000001 {
"aliases": {
"log-alias": {
"is_write_index": true
}
}
}
登录 Kibana 页面,查看该索引被相应 Policy 应用
之后,当索引达到rollover条件(7 天或 50GB),ILM 会自动创建log-000002作为新写入索引,旧索引则按策略进入 “温→冷→删除” 阶段。