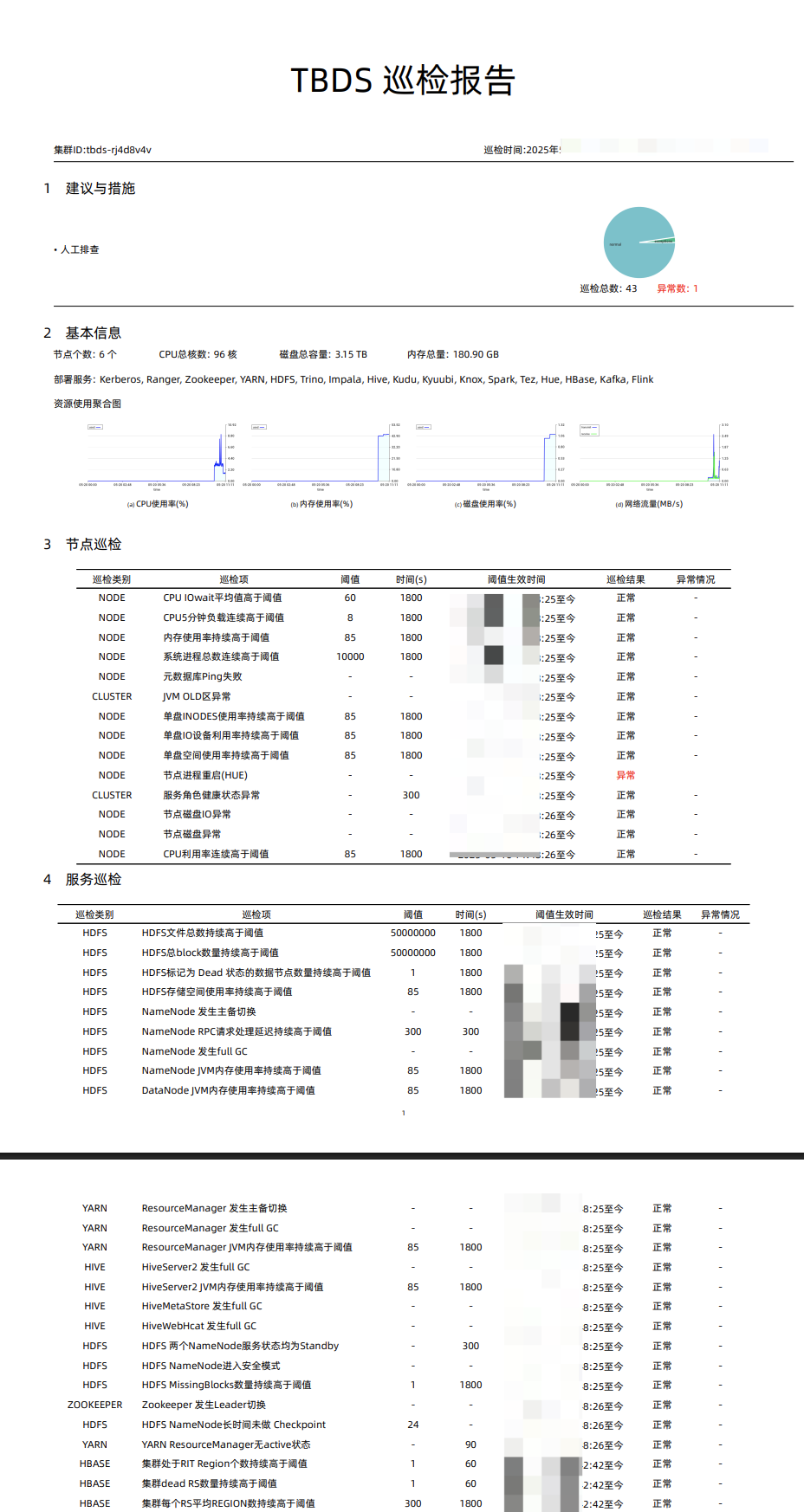
功能介绍
- 经典集群可即时或定时(按天、按周)根据已选的巡检项对集群的节点和服务进行健康检查,以便周期性掌握集群健康情况,及时对异常风险点进行处理。
- 平台提供默认巡检项,用户可按需勾选需要增加的巡检项目。
- 每次巡检任务完成后生成 PDF 格式的巡检报告,用户可以下载或删除巡检报告。
说明:
- 单个集群仅可配置一个定期巡检任务。
- 服务功能类巡检会消耗集群性能,不推荐在业务高峰期进行有耗损的巡检。
- 每个集群最多可保留200份巡检报告,超过保存的最大限额将会从最早期报告开始滚动删除。
- 定时巡检任务正在执行中时,不能修改保存配置。
巡检范围
5315版本支持的巡检范围包括:
- 集群类型:支持Hadoop 类型集群。
- 服务类型:支持 HDFS、YARN、HBase、Hive、Zookeeper组件。
- 预置巡检项:
维度 服务类型 巡检项 集群 - JVM OLD区异常 节点角色进程重启 自动伸缩策略过期 服务角色健康状态异常 自动伸缩策略执行失败 自动伸缩策略未触发 自动伸缩策略执行超时 自动伸缩扩容部分成功 引导脚本执行失败 进程被OOM killer kill 节点 - CPU利用率连续高于阈值 CPU IOwait平均值高于阈值 CPU1分钟负载连续高于阈值 内存使用率持续高于阈值 系统进程总数连续高于阈值 元数据库异常 单盘INODES使用率持续高于阈值 单盘I/O设备利用率持续高于阈值 单盘空间使用率持续高于阈值 子机UTC时间和NTP时间差值高于阈值 节点磁盘I/O异常 节点故障 故障节点自动补偿 实例硬盘异常待授权 实例运行异常待授权 子机nvme设备error 机器重启 内存OOM 内核故障 磁盘只读 ping不可达 组件 HDFS HDFS存储空间使用率持续高于阈值 NameNode 发生主备切换 NameNode 发生Full GC NameNode JVM内存使用率持续高于阈值 DataNode JVM内存使用率持续高于阈值 HDFS 两个NameNode服务状态均为Standby HDFS NameNode进入安全模式 HDFS MissingBlocks数量持续高于阈值 HDFS NameNode长时间未做 Checkpoint YARN ResourceManager 发生主备切换 ResourceManager 发生Full GC ResourceManager JVM内存使用率持续高于阈值 YARN ResourceManager无active状态 HBase 集群处于RIT Region个数持续高于阈值 集群dead RS数量持续高于阈值 集群每个RS平均REGION数持续高于阈值 HMaster 发生Full GC HMaster JVM内存使用率持续高于阈值 HBASE 两个HMaster服务状态均为Standby HMaster 发生主备切换 Hive HiveServer2 Full GC HiveServer2 JVM内存使用率持续高于阈值 HiveMetaStore Full GC HiveWebHcat Full GC ZK Zookeeper 发生Leader切换
操作步骤
- 登录 TBDS Manager,在集群列表中单击对应的集群名称进入集群详情页。
- 在集群详情页中选择集群监控 > 集群巡检可根据当前集群的节点和服务进行健康检查,用户可单击“即时巡检”进行巡检;也可单击“定时巡检设置”,配置定时巡检任务。

即时巡检
即时巡检是检查集群从某个时刻到当前时间节点和服务的健康状态并生成巡检报告。
定时巡检
- 定期巡检策略开启后,系统将自动检测每个巡检周期内集群节点和服务的健康状态并生成巡检报告。每个集群可配置一个定期巡检策略,配置更新后将覆盖历史。

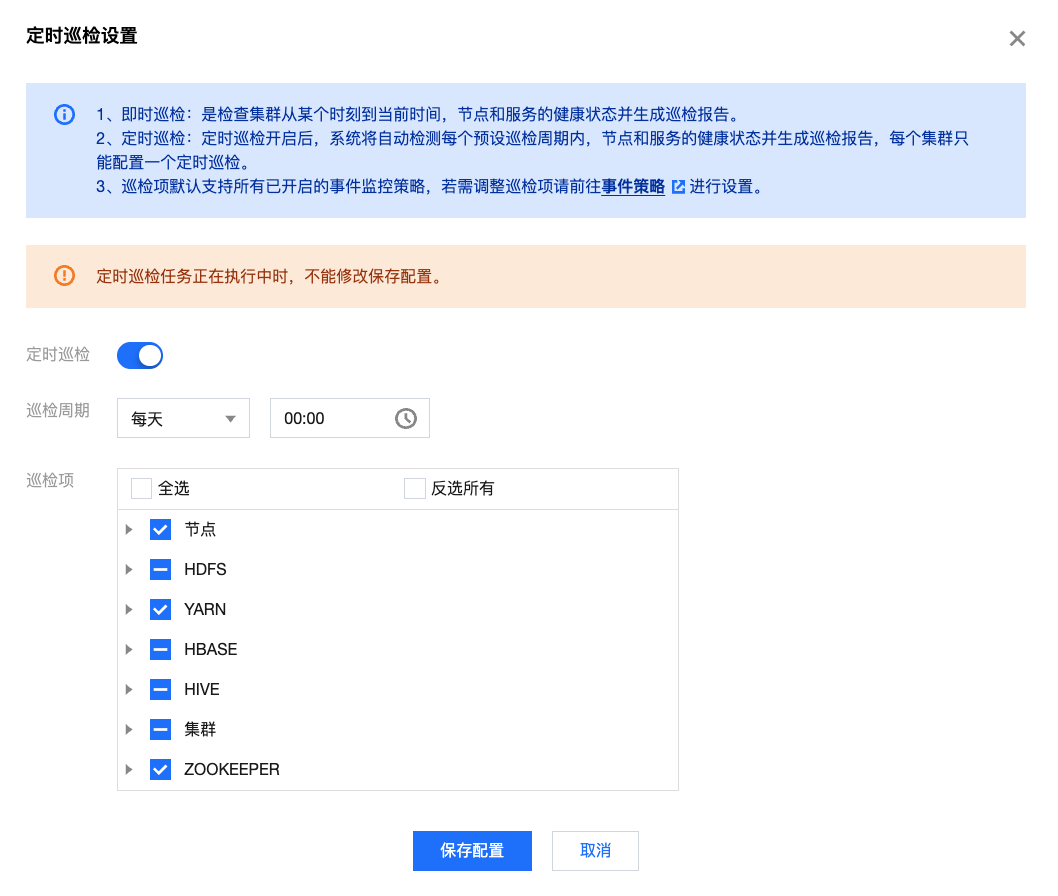
- 巡检项:默认支持所有已开启的事件监控策略,若需调整巡检项可参考 集群事件 进行设置。初始巡检项系统默认勾选所有已开启监控的事件,修改后第二次设置巡检项,默认会勾选上一次已选择的巡检项。
- 巡检报告:每次的即时巡检/定时巡检任务结束后,会自动生成一份巡检报告,该报告支持在线预览、下载、删除。