
SQL基础操作 PG模式
本节主要介绍 TDSQL PG 在PG模式下的SQL基本操作。
连接数据库
获取数据库连接配置信息,登录数据库系统:
- 登录TDSQL管理平台在左侧选择 实例管理 并点击需要登录的实例,进入 节点管理 页(分布式下选择 计算节点 页,集中式选择 数据节点 页)。
- 选择需要登录的节点IP,鼠标悬停在其右侧
 图标获得环境配置信息。
图标获得环境配置信息。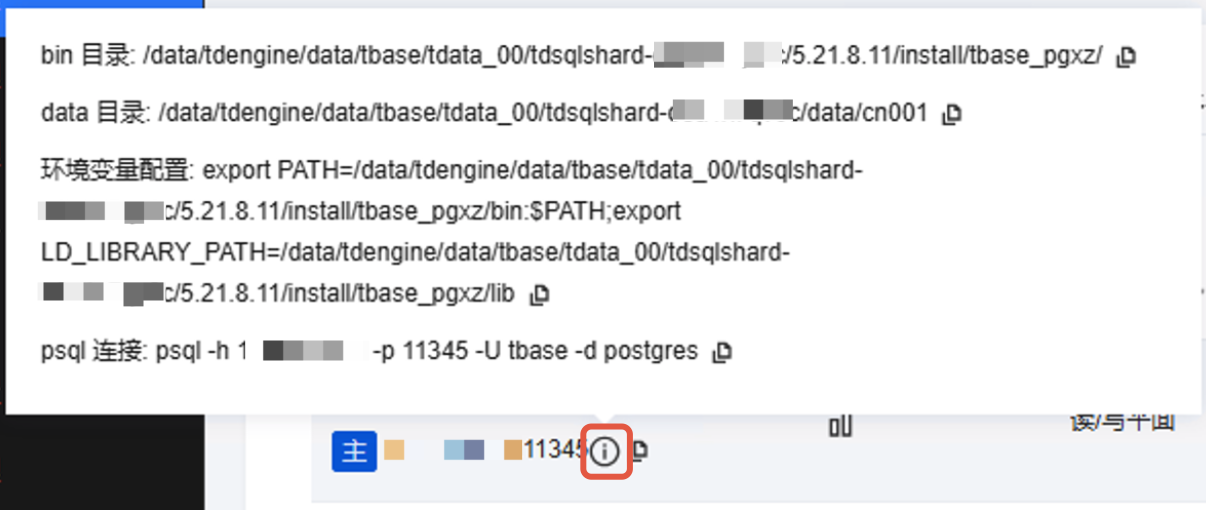
- 登录数据库节点服务器,切换到tbase用户并使用上述的export命令设置环境变量。
 图标获得环境配置信息。
图标获得环境配置信息。
su - tbase
export PATH=/data1/tdengine/data/tbase/tdata_00/tdsqlshard-o62xkfw1a0/5.21.8.11/install/tbase_pgxz/bin:$PATH;
export LD_LIBRARY_PATH=/data1/tdengine/data/tbase/tdata_00/tdsqlshard-o62xkfw1a0/5.21.8.11/install/tbase_pgxz/lib
- 在本机使用psql命令连接数据库(tbase用户一般只用于本机登录,可以创建普通用户用于业务开发)。
注意:
是连接到cn节点(后面没特别说明,所有数据库操作都是连接到cn节点)。
psql -h database_host_ip -p 11345 -U tbase -d postgres
创建用户
TDSQL PG可以用CREATE USER创建一个用户,需要使用超级用户或者具有CREATEROLE权限的用户(比如:tbase)。
- 示例:使用
create user创建用户并指定密码。
postgres=# create user mgr password 'mypassword';
CREATE ROLE
创建完成后,使用\du 展示用户信息。
postgres=# \du mgr
List of roles
Role name | Attributes | Member of
-----------+------------+-----------
mgr | | {}
可以使用ALTER USER重新设置用户密码。
postgres=# alter user mgr password 'newpassword';
ALTER ROLE
创建数据库
要创建一个数据库,需要使用超级用户或者具有CREATEDB权限的用户。
- 示例:使用
create database默认参数创建数据库。
postgres=# create database tdsql;
CREATE DATABASE
创建完成后,可以通过 \l 命令查看当前实例中的所有数据库。
postgres=# \l
List of databases
Name | Owner | Encoding | Sqlmode | Collate | Ctype | Access privileges
---------------+-------+----------+----------+------------+------------+-------------------
ora | tbase | UTF8 | oracle | zh_CN.utf8 | zh_CN.utf8 |
postgres | tbase | UTF8 | postgres | zh_CN.utf8 | zh_CN.utf8 |
tdsql | tbase | UTF8 | postgres | zh_CN.utf8 | zh_CN.utf8 |
template0 | tbase | UTF8 | postgres | zh_CN.utf8 | zh_CN.utf8 | =c/tbase +
| | | | | | tbase=CTc/tbase
template0_ora | tbase | UTF8 | oracle | zh_CN.utf8 | zh_CN.utf8 | =c/tbase +
| | | | | | tbase=CTc/tbase
template1 | tbase | UTF8 | postgres | zh_CN.utf8 | zh_CN.utf8 | =c/tbase +
| | | | | | tbase=CTc/tbase
template1_ora | tbase | UTF8 | oracle | zh_CN.utf8 | zh_CN.utf8 | =c/tbase +
| | | | | | tbase=CTc/tbase
(7 rows)
在刚创建的tdsql中进行后续操作,使用\c命令切换数据库。
postgres=# \c tdsql;
You are now connected to database "tdsql" as user "tbase".
tdsql=#
创建模式
- 标准语句。
tdsql=# create schema tbase_pg;
CREATE SCHEMA
- 扩展语法,不存在时才创建。
tdsql=# create schema if not exists tbase_pg;
NOTICE: (42P06) schema "tbase_pg" already exists, skipping
CREATE SCHEMA
表操作
创建表
使用命令create table创建表
- 不用指定shard key建表,系统默认使用第一个字段做为表的shard key
create table shared_col_table(id serial not null,nickname text);
- 指定shard key建表
create table t_appoint_col(id serial not null,nickname text) distribute by shard(nickname);
注意:
分布键选择原则
- v5.21.x支持多列分布键
- 如果有主键,则选择主键做分布键
- 如果主键是复合字段组合,则选择过滤性好的字段做分布键
- 没有主键的可以使用UUID来做分布键
- 让数据尽可能的分布得足够散
- 表不存在时才创建
create table IF NOT EXISTS t(id int,mc text);
查看表
使用\d命令查看表。
tdsql=# \d t_appoint_col;
Table "public.t_appoint_col"
Column | Type | Collation | Nullable | Default
----------+---------+-----------+----------+-------------------------------------------
id | integer | | not null | nextval('t_appoint_col_id_seq'::regclass)
nickname | text | | |
修改表
使用命令alter table修改表
示例:
- 修改表名
alter table t rename to tbase;
- 增加表字段
alter table tbase add column age integer;
- 修改字段类型
alter table tbase alter column age type float8;
- 修改表所属模式
alter table tbase set schema public;
删除表
使用命令drop table删除表
示例:当表存在时删除
drop table if exists tbase;
索引操作
创建索引
使用命令create index创建索引
示例:
- 创建唯一索引
create table t_first_col_share(id serial not null,nickname text);
create unique index t_first_col_share_id_uidx on t_first_col_share using btree(id);
注意:
非shard key字段不能建立唯一索引
- 创建多字段索引
create table t_mul_idx (f1 int,f2 int,f3 int,f4 int);
create index t_mul_idx_idx on t_mul_idx(f1,f2,f3);
查看索引
- 使用
\d命令查看索引。
tdsql=# \d t_first_col_share;
Table "public.t_first_col_share"
Column | Type | Collation | Nullable | Default
----------+---------+-----------+----------+-----------------------------------------------
id | integer | | not null | nextval('t_first_col_share_id_seq'::regclass)
nickname | text | | |
Indexes:
"t_first_col_share_id_uidx" UNIQUE, btree (id) WITH (checksum='on')
- 使用
\di命令查看索引
tdsql=# \di
List of relations
Schema | Name | Type | Owner | Table
--------+---------------------------+-------+-------+-------------------
public | t_first_col_share_id_uidx | index | tbase | t_first_col_share
public | t_mul_idx_idx | index | tbase | t_mul_idx
(2 rows)
- 使用
pg_indexes视图列出索引
SELECT
indexname,
indexdef
FROM
pg_indexes
WHERE
tablename = 't_first_col_share';
示例输出:
indexname | indexdef
---------------------------+-----------------------------------------------------------------------------------------------------------------
t_first_col_share_id_uidx | CREATE UNIQUE INDEX t_first_col_share_id_uidx ON public.t_first_col_share USING btree (id) WITH (checksum='on')
(1 row)
删除索引
使用命令DROP INDEX删除索引
drop index t_first_col_share_id_uidx;
插入数据
insert用于向一张表中插入数据,期望插入的数据可以是一条,多条或者是一个select查询的结果集。
使用INSERT INTO...命令插入数据
- 创建表
tbase并插入一行数据:
tdsql=# create table tbase(id serial not null,nickname text) distribute by shard(id);
CREATE TABLE
tdsql=# insert into tbase(id,nickname) values(1,'hello TDSQL PG');
INSERT 0 1
- 向表
tbase插入多行数据:
tdsql=# insert into tbase(id,nickname) values(2,'TDSQL PG'),(3,null),(4,'TDSQL PG good');
COPY 3
tdsql=# select * from tbase;
id | nickname
----+----------------
1 | hello TDSQL PG
2 | TDSQL PG
3 |
4 | TDSQL PG good
(4 rows)
删除数据
delete用于删除表数据,可以全部删除或者部分删除。
- 示例,带条件删除:
tdsql=# select * from tbase;
id | nickname
----+----------------
1 | hello TDSQL PG
2 | TDSQL PG
3 |
4 | TDSQL PG good
(4 rows)
tdsql=# delete from tbase where id=4;
DELETE 1
- 示例,null条件的表达方式
tdsql=# delete from tbase where nickname is null;
DELETE 1
tdsql=# select * from tbase;
id | nickname
----+----------------
1 | hello TDSQL PG
2 | TDSQL PG
(2 rows)
更新数据
update用于更新表数据,可以更新一个字段或者多个字段。
tdsql=# update tbase set nickname ='Hello TDSQL PG' where id=1;
UPDATE 1
查询数据
select用于从一张表或视图中获取数据。
使用select...from...命令查询数据
- 创建
t_grouping表并插入内容
create table t_grouping(id int,dep varchar(20),product varchar(20),num int);
insert into t_grouping values(1,'dept no1','phone',90);
insert into t_grouping values(2,'dept no1','computer',80);
insert into t_grouping values(3,'dept no1','phone',70);
insert into t_grouping values(4,'dept no2','computer',60);
insert into t_grouping values(5,'dept no2','phone',50);
insert into t_grouping values(6,'dept no2','computer',60);
insert into t_grouping values(7,'dept no3','phone',70);
insert into t_grouping values(8,'dept no3','computer',80);
insert into t_grouping values(9,'dept no3','phone',90);
- 查询
t_grouping表所有内容
tdsql=# select * from t_grouping;
id | dep | product | num
----+----------+----------+-----
1 | dept no1 | phone | 90
2 | dept no1 | computer | 80
5 | dept no2 | phone | 50
6 | dept no2 | computer | 60
8 | dept no3 | computer | 80
9 | dept no3 | phone | 90
3 | dept no1 | phone | 70
4 | dept no2 | computer | 60
7 | dept no3 | phone | 70
(9 rows)
- 按dep,product汇总,排序展示
tdsql=# select dep,product,sum(num) from t_grouping group by dep,product order by dep,product;
dep | product | sum
----------+----------+-----
dept no1 | computer | 80
dept no1 | phone | 160
dept no2 | computer | 120
dept no2 | phone | 50
dept no3 | computer | 80
dept no3 | phone | 160
(6 rows)
- 带条件查询
tdsql=# select * from t_grouping where dep='dept no2';
id | dep | product | num
----+----------+----------+-----
5 | dept no2 | phone | 50
6 | dept no2 | computer | 60
4 | dept no2 | computer | 60
(3 rows)
提交事务
事务提交用于保存对数据库的更改命令。
命令如下:COMMIT; 或者 COMMIT TRANSACTION;
例:
insert into tbase(id,nickname) values(5,'hello new TDSQL PG');
BEGIN;
delete from tbase where id=5;
COMMIT;
注意:
在COMMIT执行之前,tbase表中id为5的记录会被另一会话查询到。
回滚事务
事务回滚用于撤销尚未保存到数据库的命令。
命令语法如下:ROLLBACK; 或者 ROLLBACK to savepoint_name;
例1:
BEGIN;
delete from tbase where id in (1,2);
select * from tbase;
ROLLBACK;
select * from tbase;
注意:
在ROLLBACK执行之后,事务对数据的删除不会保存到数据库中。
例2:
BEGIN;
delete from tbase where id =1;
select * from tbase;
savepoint A;
delete from tbase where id =2;
select * from tbase;
ROLLBACK to A;
COMMIT;
注意:
在ROLLBACK to A;执行之前同一进程查询不到id为1和2的数据。回滚到保存点之后,id为2数据可查询到。ROLLBACK to savepoint_name;不会结束事务,需使用COMMIT;提交事务。